僾儔僀儀乕僩偱僱僞偵忋偑偭偨偺偱
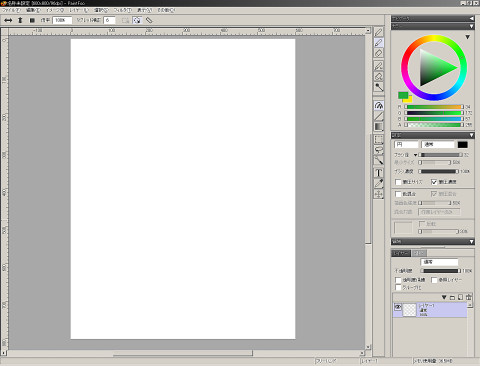
PaintFoo ver.0.68a [2025/11/01斉]
慜夞偺傕偺偐傜抳柦揑側僶僌偑2屄強捈偭偰傑偡丄1偮偼UI偺摿掕偺1僪僢僩傪僋儕僢僋偡傞偲僋儔僢僔儏偡傞偲偄偆傕偺丄 傕偆1偮偼摿掕偺忦審壓偱儗僀儎乕偺寢崌寢壥偑晄惓妋偵側傞偲偄偆傕偺.
屻偼僌儔僨乕僔儑儞僣乕儖偺婡擻捛壛傗嬋慄傾儖僑儕僘儉偺挷惍 (強堗G2嬋慄偩偑丄摿惈偼傎傏偦偺傑傑偱僐儞僩儘乕儖惈傪戝暆偵夵慞)丄婔偮偐偺僼傿儖僞偺僒儞僾儕儞僌傾儖僑儕僘儉偺夵慞傗敳杮揑尒捈偟丄 僽儔僔偺摟柧搙崌惉幃偵幚尡僐乕僪偑暣傟偰偄偰傗傗晄惓妋側擹搙偵側偭偰偄偨偺傪夵慞 (墘嶼揑偵偼嬤帡儌僨儖側偺偱慡偰偺働乕僗偱尩枾偵惓妋偱偼柍偄偑)丄拞墰偑墯傫偩僽儔僔傪攑巭偟偰偳偙傑偱奼戝偟偰傕嫬奅偑僼儔僢僩偵側傞僽儔僔傪捛壛摍乆.
崱偺強壗偐彂偔偩偗偺梋椡偑柍偄偺偱娙扨偵丄儀僋僞乕昤夋宯偺儔僀僽儔儕傪嶌偭偰偄偰昅埑偵懳墳偟偨嬋慄偺椫妔傪儀僋僞乕宍幃偱惗惉偡傞儔僀僽儔儕偑偱偒偨丄 昅埑偺妱傝摉偰偼惂屼揰扨埵偱嬋慄偺挿偝傕偟偔偼t抣偺偄偢傟偐慖戰幃偱曗娫壜擻. 尦乆偼SVG傪埖偆栚揑偱僗僩儘乕僋傪儀僋僩儖僨乕僞偺傑傑埖偆儔僀僽儔儕偩偭偨偑丄柺敀偦偆側偺偼偙傟偱昅埑傪娷傓僀儔僗僩側偳偺慄夋傪偦偺傑傑偺尒偨栚偱SVG偲偟偰 彂偒弌偣傞嵽椏偑懙偭偨帠偱丄偮傑傝偁傞掱搙嵟廔揑側嶌昳偺僾儗僛儞僥乕僔儑儞傪桳尷夝憸搙偺僺僋僙儖夋憸偱偼柍偔儐乕僓乕僒僀僪偱傕柍尷夝憸搙偺儀僋僞乕偲偟偰庢傝埖偆帠偑壜擻偲側傞. 偨偩偟桳岠妶梡偡傞偵偼僜僼僩偺曗彆偼晄壜寚偱丄忋偵彂偄偨G2嬋慄偲偺慻傒崌傢偣傕幚偵嫮椡側偺偩偑丄帺慜偺僜僼僩偵儀僋僞乕宍幃傪幚憰偡傞偺偼尷傝側偔柺搢側偺偱丄愨懳偵傗傝偨偔柍偄偺偑僱僢僋X-<
尦乆儗僀儎乕偵暋悢偺庬椶偺僨乕僞傪擖傟崬傔傞愝寁偵側偭偰偄側偄偺偱摉嵗側偵偐傪傗傞梊掕偼柍偄偑丄帺暘揑偵抦幆晄懌偩偭偨儀僋僞乕宍幃偵娭楢偟偨曌嫮傕傛偆傗偔柺敀偔丄偦偟偰僕儗儞儅傕弌偰偒偨偲傑乕偦傫側僇儞僕丄偦偙偦偙偼妝偟傫偱偄傞(偙偙偑廳梫)
PaintFoo ver.0.68a [2025/04/03斉]
傎傏惗懚妋擣傒偨偄側傕偺(徫)
...偙偺1擭偦傟側傝偵庤傪擖傟偨偮傕傝偩偭偨偑丄1擭慜偵忋偘偨傕偺偲斾妑偟偰傕梋傝曄傢偭偨報徾偑柍偄X-<
彜梡僜僼僩偑儊僕儍乕僶乕僕儑儞傾僢僾偺搒搙尒偨栚傪曄偊傞棟桼偑椙偔敾傞婥偑偡傞(徫)
尒偰偺捠傝丄崅dpi娐嫬偱偺GUI偺壜曄昞帵偵懳墳偟偰偄側偄偺偱幚幙愭嵶傝偱偁傞丄 偙偺曈帺慜儔僀僽儔儕偱傕崻姴傪側偡晹暘偱偁傞偺偱丄偳偆愝寁偟偨傕偺偐枹偩偵帺暘偺拞偱僀儊乕僕偑屌傑偭偰偄側偄:-<
屻偼傑偁TIFF偲PNG偺幚憰傪帺慜偺幚憰偵愗傝懼偊偰丄傾僯儊乕僔儑儞弌椡偵棈傓僶僌偺廋惓偲 APNG懳墳偵敽偄尭怓儖乕僠儞偺慡僼儗乕儉傪懳徾偵偟偨摑寁忣曬傊偺懳墳丄 偮偄偱偵webp偵懳墳偟偨傝丄杮摉偼avif傕懳墳偟偨偐偭偨偑丄儔僀僽儔儕偺僐儞僷僀儖偵怓乆僀儞僗僩乕儖偑昁梫偱払惉偱偒偰偄側偄X-<
屻偼擮婅(?)偺僈僂僗傏偐偟偺慖戰椞堟偵傛傞傏偐偟検偺曄摦傪幚憰丄怓乆嬤帡偼偁傞偺偩偑
(儅僗僋偑掅廃攇偱偁傟偽忯傒崬傒椞堟偺僐僸乕儗儞僔偑婜懸弌棃丄崅廃攇偺応崌偼僲僀僘偵忯傒崬傑傟傞偺偱偦傟掱偼栚棫偨側偄)
忬懺偵傛傝曄側傾乕僥傿僼傽僋僩傪惗偠傞帠傕柍偔丄懡彮儊儌儕偼怘偆偑掕悢帪娫偱偺張棟偵側傞;-)
偦偺懠怓乆廋惓
嫀擭偺嵟戝偺惉壥偼擮婅偱偁偭偨儔僗僞乕 to 儀僋僞乕曄姺傪幚憰偟偨帠偩偑丄忋偺僜僼僩偵偼儀僋僞乕婡擻偼柍偄偺偱堦愭偢憅屔峴偒.
幚嵺偵嶌偭偰傒偨強偱偼丄儀僋僩儖嵗昗偱偺椫妔捛愓屻丄摨堦捈慄忬偵偁傞揰傪弶婜僌儖乕僾偲偟偰傑偲傔 僌儖乕僾摨巑傪嵟彫擇忔朄偱僼傿僢僥傿儞僌偟偰嫋梕岆嵎撪偱僌儖乕僾摨巑傪楢寢偝偣傞傛偆側嬶崌偱偦傟側傝偵忋庤偔峴偔柾條偱偁傞.

偙傟偑

偙乕側偭偰

偙偆側傞(嵟屻偺夋憸偼SVG)
恖娫偑曇廤偡傞慺嵽傪嶌傞憐掕側偺偱宍偺惓妋偝傛傝傕惂屼揰偺埖偄堈偝傪桪愭偟丄偁傞掱搙惃偄偑偁傞晹暘偵偮偄偰偼嫋梕岆嵎偵壛懍搙傪晅偗傞帠偱戝偒偔娫堷偄偰偄偨傝偡傞.
惗惉偝傟偨SVG傪奼戝偟偰尒傞偲丄嵞尰偝傟偰偄傞偺偼偣偄偤偄尦夋憸僒僀僘偺忣曬偩偗偱丄1pixel偵枮偨側偄忣曬偵偮偄偰偼 揔摉偵曗娫偝傟偰偄傞帠偑敾傞. 偙傟偼AI偵傛傞挻夝憸偱傕摨條偺報徾傪庴偗傞偺偩偑 岆杺壔偝傟傞偺偼偣偄偤偄2攞掱搙偺夝憸搙傑偱偱丄傗偼傝忣曬検偑憹偊偨儚働偱偼柍偄偲幚姶偡傞(柺敀偔偼偁傞偺偩偑).
...愜妏嶌偭偨偺偩偐傜丄壗偲偐柺敀偄巊偄摴偑巚偄偮偗偽椙偄偺偩偗偳:-<
# 梋傝帡偰偄側偄偺偼丄偙傟偱傕堦惗寽柦柾幨偟偨寢壥側偺偱嫋偟偰梸偟偄orz
## 僱僢僩偺枱夋偺揮嵹傗twitter偺傾僀僐儞偱彑庤偵挊嶌暔傪巊偭偰偄傞偺偲偐尒傞偲丄嵟嬤偼偦傟掱恄宱幙偵側傞昁梫偼柍偄偺偐傕偟傟側偄偑丄 屆偄恖娫側偣偄偐丄岞嫟偺僱僢僩偵忋偘傞帪揰偱屄恖揑暋惢丒東埬偺斖埻奜偲偄偆姶妎偑嫮偄. 偱傕偦偺姶妎偱崱偺僱僢僩傪庢傝掲傑偭偨傜偦傟偙偦夡柵偩傠偆偟丄柧妋側婎弨偼柍偔嬻婥姶偩偗偱丄幚嵺偺強偳偆側偺偩傠偆偐偲寢峔恀寱偵擸傫偱偟傑偆.
...偲偄偆儚働偱傕柍偄偺偩偗偳
帺暘梡偵嶌偭偰偄傞儁僀儞僩僜僼僩傪偙偪傜偵傕忋偘偰傒傞
PaintFoo ver.0.68a [2024/01/30斉]
Windows2000 SP4埲崀+SSE2懳墳偺CPU岦偗偺32bit傾僾儕偱丄昅埑傪巊梡偡傞応崌偼Wintab懳墳偺僞僽儗僢僩偑昁梫.
擔晅偵"2007-2024"偲偁傞偺偱傕偆17擭嶌偭偰偄傞儚働偱丄惓捈壗偺庺偄偩偐偲偄偆婥傕偡傞偑(嬯徫)
崱夞帺暘偺拞偱堦嬫愗傝偮偄偨偺偱偲偄偆偐丄偦傫側僇儞僕偱丄傑偀堦墳嶐崱偺儁僀儞僩宯僜僼僩偲斾妑偟偰傕戝奣偺帠偼偱偒傞傛偆偵偟偨偮傕傝;-)
姶妎揑偵偼僼傿儖僞偑偁偲20屄掱懌傝側偄僇儞僕丄PhotoShop偱尵偆強偺傾乕僥傿僗僥傿僢僋宯偲偄偆偐婛惉夋憸偵僨傿僗僩乕僔儑儞傪壛偊偰慺嵽偲偟偰埖偆晹暘偑偳偆偵傕庛偄偺偑擸傑偟偄:-<
Exif側傫偐偼偳乕偟傛偆偐側丄偲偐. 儔僀僽儔儕偲偟偰偼姰惉偟偰偄傞偺偩偑丄偳偆偵傕尒偣曽偑擄偟偄. 壗偲側偔偱偼偁傞偗偳9妱偺儐乕僓乕偵偲偭偰偼偳偆偱傕椙偄婡擻偱丄巆傝1妱偵偼昁梫偱傕丄偦偺堊偵巆傝9妱偑儚儕傪怘偆 (Exif偵懳偟柍撢拝側帠偱敪惗偡傞儕僗僋) 傛偆側婡擻側婥偑偟偰丄偦偺曈傪夝徚偡傞尒偣曽偲偄偆偺偑偳偆偵傕巚偄偮偐側偄.
忋偺傕偙傟偐傜偳偆恑傔偰峴偔偐偲偐柧妋側價僕儑儞偑偁偭偰傗偭偰偄傞儚働偱偼柍偄偺偩偗偳丄僾儘僌儔儉偺妛廗傗巚偄偮偄偨傾儖僑儕僘儉傗儚乕僋僼儘乕偺専徹側偳傕寭偹偰偄傞傕偺偺丄寢嬊偼庯枴偱僾儔儌僨儖慻傫偱偄傞偺偲摨偠傛偆側姶妎偐傕偟傟側偄.
# 嶌偭偰偄傞娐嫬偑偪傚偭偲屆偄(傎傏20擭慜偺儅僔儞)側偺偱夋柺偑4:3偵崌傢偣偰儗僀傾僂僩偝傟偰偨傝偼偛垽沢:-P
僱僢僩偱専嶕偡傞偲HDTV(ITU-R BT.709)偵婎偯偔學悢偲偟偰弌偰偔傞幃偱埲壓偺幃偑偁傞偺偩偑
Y = 0.222015*R + 0.706655*G + 0.071330*B
仸幚嵺偼偙偺慜屻偵僈儞儅曗惓傪娷傒儕僯傾RGB偲偡傞塣梡偑懡偄偑偙偙偱偼婰弎偲偟偰徣棯偟偰偄傞.
偙偙偱巊梡偝傟偰偄傞學悢偺抣偵尒妎偊偑柍偐偭偨偺偱丄婥偵側偭偰寁嶼偟偰傒偨強丄埲壓偺xy抣偵偰
| W (D65) | 0.312713 | 0.329016 |
| R | 0.64 | 0.33 |
| G | 0.29 | 0.60 |
| B | 0.15 | 0.06 |
偙偺帪偺帺慜儔僀僽儔儕偱偺RGB->XYZ曄姺儅僩儕僋僗偺寁嶼寢壥偑傎傏堦抳偡傞抣偵側傞 (側偍嶲徠岝尮偼D65偱D50傊偺弴墳偼柍偟).
0.43057387215726, 0.341550021754784, 0.178325324363055 0.222014652831087, 0.706655217423691, 0.071330129745222 0.0201831502573716, 0.129553456527677, 0.939180041645423 |
偙偺幃偵婎偯偔偲偡傞偲忋偺xy抣偼HDTV偺學悢偱偼柍偔PAL婯奿 (ITU-R BT.470) 偺學悢抣偵側傞敜偩偑丄夁嫀偵HDTV婯奿偱傕偙偺抣偑嶲徠偝傟偰偄偨偺偐偵偮偄偰偼巆擮側偑傜徻嵶晄柧.
偨偩昿斏偵寁嶼偡傞抣偱偼柍偄偺偱丄堦墳偺帺暘梡偺儊儌偲偟偰.
# 扐偟HDTV偲偟偰傕 G=[0.30, 0.60] 偵側傞偩偗 (婯奿偵崌傢偣傞側傜敀怓揰偺寘悢傪崌傢偣傞応崌傕偁傞偑) 側偺偱墘嶼偲偟偰偺僘儗偼偦傟掱偼戝偒偔偼側偄偺傕帠幚.
側偍忋偺幃偼PhotoShop偺僌儗乕僗働乕儖壔曽幃偲偟偰徯夘偝傟傞帠傕偁傞傛偆側偺偩偑丄彮側偔偲傕僇儔乕僾儘僼傽僀儖懳墳埲崀偺 (偙偙20擭掱偺) PhotoShop偵偮偄偰偼岆傝偱偁傞偺偱拲堄.
PhotoShop偺曽幃偼嶌嬈RGB偺怓嬻娫傪CMM偵偍偗傞D50愙懕嬻娫偵曄姺偟偨僌儗乕僗働乕儖曄姺偵側傞丄扐偟忋偺幃偼sRGB偵偍偗傞CMM偱偺曄姺偵斾妑揑嬤偄寢壥傪梌偊傞偺偱PhotoShop偺嶌嬈嬻娫偑sRGB偵愝掕偝傟偰偄傞応崌偼 (僈儞儅曗惓傕嬤偄傕偺傪梡偄傟偽) 帡偨寢壥偵側傞偲偄偆偩偗偺榖(仸1).
AdobeRGB傗Display P3摍偺夋憸偱偼忋偺幃傪巊偭偰曄姺偡傞偲PhotoShop偺曄姺寢壥偲偼慡偔堘偭偨夋憸偵側傞偺偱拲堄.
仸1) PhotoShop偺曄姺偱偼RGB怓嬻娫偐傜僌儗乕僾儘僼傽僀儖偺掕媊偵廬偭偨怓嬻娫傊偺曄姺偲偡傞堊 (乽愨懳揑側怓堟傪堐帩乿埲奜偱偼) D50弴墳傪慜採偲偟偨曄姺偑峴傢傟丄慜屻偺僈儞儅曗惓傕偦傟偧傟曄姺尦丒愭偺傕偺偑巊傢傟傞丄偙傟偼杮幙揑偵偼報嶞梡偺僌儗乕嬻娫傊偺曄姺偱偁傝丄摨堦RGB嬻娫撪偱偺僌儗乕僗働乕儖曄姺偲偼柧妋偵嬫暿偝傟傞傋偒傕偺偲側傞.
傑偨僌儗乕偺僈儞儅宍忬偑昞帵宯偲堎側傞応崌 (椺偊偽sRGB偲GrayGamma22摍) 偱偼昞帵偵偍偗傞曄姺傕娷傔偰峫偊偹偽惓妋側僌儗乕夋憸偺昞帵偼峴偊側偄帠偵傕拲堄偑昁梫.
昞戣偺捠傝丄挷傋儌僲傪偟偰偄偨強丄懎偵 乽NTSC壛廳暯嬒偵傛傞僌儗乕僗働乕儖曄姺乿 偲偟偰採帵偝傟傞埲壓偺幃
Y = R*0.298912 + G*0.586611 + B*0.114478
偵偮偄偰擔杮偺撈帺儖乕儖 (幚嵺偙偺學悢傪専嶕偡傞偲杦偳偑擔杮岅偺僒僀僩側偺偼帠幚) 偲偐崻嫆偑柍偔Wikipedia偵徯夘偝傟偰偄傞學悢偲偼堘偭偰偍偐偟偄偲偐丄宱尡懃偱嶌傜傟偨學悢偩偲偐丄彮乆婥偵側傞撪梕偑栚偵晅偄偨偺偱摫弌偺崻嫆傪彂偄偰偍偔丄傒偨偄側.
偲尵偭偰傕壗傜偛戝憌側榖偱偼側偔偰NTSC偺xy掕媊偵偮偄偰悢抣偺惛搙傪
| W (C岝尮) | 0.310063 | 0.316158 |
| R | 0.67 | 0.33 |
| G | 0.21 | 0.71 |
| B | 0.14 | 0.08 |
偲偟偰RGB->XYZ曄姺傪媮傔傟偽偙偺學悢偑弌偰偔傞偲偄偆偩偗偺榖.
xy掕媊偐傜曄姺峴楍傪媮傔傞曽朄偵偮偄偰偼徣棯偡傞偑(仸1) 椺偊偽帺慜偺怓曄姺儔僀僽儔儕偱寁嶼偟偨曄姺峴楍偺僟儞僾偼埲壓偺捠傝
0.606881244882208, 0.173504578784877, 0.200335840817129
0.298911657927057, 0.586610718748869, 0.114477623324074
0, 0.0660969823942388, 1.11615682740972
|
恀偺堄枴偺桳岠寘悢偺昡壙偼PC忋偱偺楢懕揑側寁嶼偱偼旕忢偵擄偟偄偑丄偙偺Y惉暘偵娭偡傞學悢傪慜弎偺NTSC掕媊偺敀怓揰偲摨條6寘傑偱偱娵傔傞偲慜弎偺
Y = R*0.298912 + G*0.586611 + B*0.114478
偲偄偆幃偑弌偰偔傞丄偙偺応崌學悢偺崌寁偑 1.000001 偲側傝1.0傪僆乕僶乕偡傞偺偱丄偦傟偑婥帩偪埆偄応崌偵偼3惉暘偄偢傟偐偺學悢傪0.000001尭偠傞帠偵側傞偑丄忋婰寁嶼偺捠傝娵傔偺懳徾偲側傞寘偼偄偢傟傕 6,7,6 偲嬤愙偟偰偄傞偺偱丄壗傟偐偺惉暘偵榗傒傪墴偟晅偗傞偺傕婥帩偪埆偄応崌偵偼旝彫抣側偺偱柍帇偟偰偟傑偆曽朄傕偁傞 (幚嵺偵偙偺幃傪揔梡偡傞抣偺惛搙傗宆偵埶傞(仸2))
側偍偙傟傪3寘偱娵傔傞偲
Y = R*0.299 + G*0.587 + B*0.114
偲丄偍撻愼傒偺學悢偑弌偰偔傞.
忋婰偵懳墳偡傞YUV(or YCrCb)偺曄姺幃偑梸偟偄応崌偼掕媊偵廬偭偰 (B-Y), (R-Y) 傪朷傓抣堟偱僗働乕儖偟偰傗傟偽椙偄 (扐偟壗傜偐偺婯奿傗巇條偵崌傢偣傞応崌偼丄偦偺巇條偵廬偆帠).
仸1) 娙扨偵彂偔偲3巋寖偺xy嵗昗偐傜xyz偺儅僩儕僋僗傪媮傔丄偦傟偑敀怓揰埵抲偱敀怓揰偺XYZ偵崌偆傛偆僗働乕儕儞僌偟偰傗傟偽媮傔傞曄姺偑摼傜傟傞.
仸2) 傑偀旕忢偵棎朶側昞尰側偺偩偑 (PC忋偱偺姷椺揑側) 桳岠寘悢偺昞尰偲偟偰偼惓偟偄儚働偱丄忋偺學悢昞尰帺懱偵嚓醨偑偁傞儚働偱偼柍偄偲偄偆強丄偨偩彮乆埖偄擄偄學悢偱偁傞帠偼帠幚.
栜榑丄嶲徠偡傞尦偺xy抣偺惛搙偵傛偭偰偼學悢偵僘儗傪惗偠傞儚働偱丄椺偊偽嶲徠敀怓揰偺抣傪1寘尭傜偟偰 [ 0.31006, 0.31616 ] 偲偟偨応崌偵慜弎偺儔僀僽儔儕偱偺寁嶼寢壥偼
0.606863809295618, 0.173507280955537, 0.200334881408764
0.298903070250081, 0.586619854659197, 0.114477075090722
0, 0.0660980117925857, 1.11615148213454
|
偲側傝丄偦偙偦偙偺僘儗偑弌偰偔傞帠偵側傞. 偙偺曈傝偑偲傕偡傞偲學悢偺掕媊偑堦抳偟側偄偺偱偍偐偟偄偲偄偭偨榖偑弌偰偔傞梫場偵側偭偰偄傞偺偐側乕偲偐巚偭偰傒偨傝.
側偍嵟屻偵側傞偑偙偺曽朄偼偁偔傑偱NTSC學悢傪 乽棙梡偟偨乿 婸搙丒怓嵎暘棧曄姺偱偁偭偰僇儔乕僾儘僼傽僀儖摍傪梡偄偨愨懳怓嬻娫偱偺怓尩枾惈傪斀塮偟偨 NTSC->僌儗乕僗働乕儖偺曄姺偲 乽摍壙偱偼柍偄乿 偺偱崿摨偵拲堄丄CMM偵偍偗傞曄姺偼僈儞儅傗徠柧偺曄姺 (愙懕嬻娫偑D50偱偁傞偺偱D50徠柧偵弴墳偟偨嬻娫偱敀怓揰偵怢傃傞捈慄忋偺揰偲偟偰僌儗乕僗働乕儖偑寁嶼偝傟傞) 偑峴傢傟傞堊丄扨弮偵忋婰傪揔梡偟偨傕偺偲偼堎側傞奒挷僶儔儞僗偺夋憸偵側傞.
傑乕妱偲偳偆偱傕椙偄榖偱偼偁傞偟丄庩峏偵偁偘偮傜偆偺傕偳偆偐偳偆偐偲巚偆偺偩偑丄偙偺學悢偺悢帤偑峀傑偭偨偺偑儈乕儉偱偁傞側傜丄偙傟偵偮偄偰崻嫆偑柍偄偲偡傞僨儅偑峀傑傞偺傕儈乕儉偱偁傞偺偱丄堦墳偪傖傫偲偟偨崻嫆偑偁傝丄宱尡懃偱偼柍偔掕媊偐傜柧妋偵摫弌偱偒傞抣偩偲彂偄偰偄傞忣曬傕偁偭偨曽偑椙偐傠偆丄傒偨偄側偦傫側僇儞僕偱.
僄儞僕儞揑偵傗傗摿庩(仸1)側偺偱幚憰偵擄偺偁偭偨巜愭僣乕儖傪 (敿偽柍棟栴棟) 幚憰偟偰傒傞僥僗僩. 桭恖偺榖偵傛傞偲墛側傫偐偺昞尰偵曋棙傜偟偄. 帋偟偵傗偭偰傒偨強偱揔摉偵揾傝捵偟偨傕偺傪5暘掱偐偒夞偟偰偙傫側嬶崌.

偆傫丄僋僙偼偁傞偗偳傑偀埆偔側偄偐傕偹. 懠偺晹暘偱帺暘偺僜僼僩屌桳偺摿惈傪棙梡偟偰偄傞晹暘偑偁傞偺偱昁偢偟傕巜愭僣乕儖側傜偳傫側僜僼僩丒幚憰偱傕偙偆側傞僇儞僕偱傕柍偄偺偩偗偳丄傑偁僐儞僩儘乕儖壜擻惈偺儃乕僟乕側偺偼擣傔傞偗偳儓儗傞偺偲偐傕寢峔廳梫偱偡傛丄傒偨偄側;-)
側偍巜愭僣乕儖偼捠忢偺僽儔僔昤夋偱偼堄幆偟側偔偰椙偄晹暘偑婔偮偐栤戣偵側傞偺偩偑丄晜摦彫悢嵗昗偲僽儔僔偺傾儞僠僄僀儕傾僗傾儖僑儕僘儉偲偺憡惈偺栤戣傊偺懳張偼尷掕揑丄1pix偲偐偩偲嫮搙100%偱傕偐偐傝偑庛偔帇擣偱偒側偔側傞栤戣偑偁傞偑 (尰峴偺僽儔僔宍忬偱偼2pix埲壓偑塭嬁偑嫮偄) 尰峴偱偼偙傟偼懳張偟側偄丄2pix埲壓偱偐偮嫮搙100%偺忬懺傪巊梡偡傞働乕僗偼嬌傔偰尷掕揑偲敾抐偟偨堊丄堦墳偙傟偵懳偡傞懳張傕巚偄偮偄偰偼偄傞偺偩偑張棟偑2攞偵側傞忋偵僽儔僔宍忬偛偲偱偺僠儏乕僯儞僌偑昁梫偵側傞堊丄偦偙傑偱偺儊儕僢僩偼柍偄偲敾抐:-<
側偍巜愭僣乕儖偲偄偆偲怓傪傏偐偡梡搑偑巚偄偮偔偐傕偟傟側偄偑丄偙傟埲奜偵幨恀偺儗僞僢僠偱嫮搙傪100%偲偐偵偡傞偲恖暔偺栚傗岥傪戝偒偔偟偨傝偡傞偺偵巊偊偨傝傕偡傞. 偲偄偆偐扨側傞怓偺堷偒偢傝偩偗側傜懠偺婡擻偱 (摨偠昞尰偵偼側傜側偄傕偺偺) 戙梡偱偒傞偺偱偙偪傜偑柍棟傪墴偟偰尰峴偺僽儔僔僄儞僕儞偵幚憰偟偨棟桼偱傕偁偭偨傝偡傞(徫)
偙傟埲奜偵偼忋庤偔巊偊偽夋憸偺揾傝僷僞乕儞偺帩偮僐儞僺儏乕僞偵傛傞儁僀儞僥傿儞僌摿桳偺僽儔僔傾儖僑儕僘儉偺 (尰幚偺夋嵽偵懳偡傞) 扨弮偝傗懳徧惈傪岆杺壔偡偺偵傕巊偊傞偐傕偟傟側偄丄偨偩僐儞僩儘乕儖偺娤揰偐傜偡傞偲偁偔傑偱曗彆揑偵丄偱偼偁傞偑丄偲偄偭偨強;-)
偟偐偟崱夞僽儔僔僄儞僕儞偵庤傪擖傟偰丄曽幃揑偵儅僘偐偭偨屄強傕婔偮偐廋惓偟偨寢壥丄尰嵼偺傾僾儕偲偟偰偺僨僓僀儞 (not 愝寁;-) ) 偱偼尷奅偑尒偊傞晹暘傕弌偰偒偰偄傞偺偱偳乕偟偨傕偺偐偲偄偆強丄晹暘揑偵偼尒憲傝偲偟偰傕椙偄偐傕偟傟側偄偑丄偝偰X-<
仸1) 摉弶儁僀儞僩僜僼僩偺抦幆偑柍偄忬嫷偱0偐傜嶌偭偨偺偱丄崱怳傝曉傞偲寢峔峝捈偟偰偄傞曽幃偱丄崱偐傜嶌傞偲偟偨傜偙偺曽幃偼庢傜側偄偩傠乕側偲偄偆僇儞僕側偺偩偗偳丄偙偺晹暘偑幚偼怓崿崌偵偍偗傞怓偺怢傃嬶崌偺僉儌偵 (寢壥揑偵) 側偭偰偄傞偺偱嶌傝捈偣偽椙偄偲偄偆儚働偱傕柍偄偺偑壗偲傕壗偲傕. 堦斒揑側幚憰偱摨條偺昞尰傪傗傠偆偲偡傞偲崱搙偼偙偺晹暘偑傗傗偙偟偔側傞偺偱僙僆儕乕偵偼斀偡傞偗偳丄偙偆偄偆偺傕偁偭偰傕椙偄偐偲傕巚偭偰傒傞. 傕偆彮偟僗働乕儖傾僢僾偝偣傞偲偙偺曽幃偩偲摢懪偪偑弌堈偄偺傕帠幚側偺偩偑;-)
婥偑晅偗偽愭偺擔婰偐傜婛偵敿擭偑宱夁偟偰偄傞丄擭楊偺偣偄偐嵟嬤帪娫偺宱夁偑傗偗偵懍偄. 偦傠偦傠恀柺栚偵怓乆側傕偺傪惛嶼偟側偑傜摦偔帠傪峫偊偨曽偑椙偄偺偐傕偟傟側偄:-<
愭偺擔婰傪彂偄偰埲棃偙偙悢廡娫掱Unicode傪惓妋偵埖偆堊偺曽朄榑偵偮偄偰怓乆峫嶡拞丄惓婯摍壙惈 + full casefolding(壜曄挿曄姺)傪埖偆応崌偵偳偺傛偆偵埖偊偽尰忬偺曽朄榑偐傜戝偒偔僐僗僩傪堩扙偟側偄宍偱埖偊傞偐偲峫偊偰偄傞偑丄偳偆偵傕寢榑偼朏偟偔側偄:-<
摿偵嵟埆側偺偼僷乕僒偺嶌惉摍偺張棟偱丄椺偊偽暥帤傪僄僗働乕僾偡傞応崌捠忢側傜'\'偵懕偄偰1暥帤撉傒丄偙偙偱 'a' 偑棃傟偽 '\a' 偲偟偰儀儖僐乕僪偵曄姺偱偒傞偺偩偑丄Unicode寢崌暥帤傪埖偆応崌偵偼1暥帤撉傫偱 'a' 偑棃偨帪揰偱偼偦傟偑 'a' 偱偁傞偐敾傜側偄偲偄偆帠偵側傞丄椺偊偽 'a' 偺屻偵 U+0304偑棃偨応崌 (偐偮屻懕偑寢崌暥帤偱偼柍偄応崌) 偼丄偙傟偼 U+0061 U+0304偺暥帤偱偁傝 U+0101偺暥帤偲摍壙偵側傞丄偮傑傝昞婰偲偟偰偼 '\ā' 偲側偭偰偄傞.
---------------
...偲傑偀偙偙傑偱彂偄偰昞戣偺審側偺偩偑丄Unicode偱偼 婎杮暥帤+寢崌暥帤*n 偺慻傒崌傢偣偑惓偟偄暥帤偱偁傞偐偼婯掕偟偰偄側偄丄偮傑傝偳偺傛偆側暥帤傕 婎杮暥帤+寢崌暥帤*n 偲偟偰廋忺偝傟偨丄埥偄偼偁傞尵岅寳偱堎側傞暥帤偲偟偰埖傢傟傞1暥帤偵側傝摼傞.
傑偨愭擔彂偄偨捠傝慡偰偺暥帤偵偮偄偰寢崌 (崌惉) 嵪傒偺撈棫偟偨暥帤 (僐乕僪億僀儞僩) 偑掕媊偝傟偰偄傞栿偱傕柍偄.
傛偭偰Unicode偺寢崌暥帤巇條傑偱娷傔偰僒億乕僩偡傞応崌1暥帤偺扨埵偼嵟掅尷 婎杮暥帤+寢崌暥帤*n 偲偟偰埖偆昁梫偑偁傞 (偙傟埲奜偵奼挘彂婰慺僋儔僗僞偲偄偆傛傝峀斖側1暥帤偺掕媊傕偁傞偑丄偙偪傜偼儐乕僓乕偺堄幆偡傞1暥帤偺奣擮偵嬤偄偺偱偙偙偱偼徣棯(仸1)) 偙傟偼寛偟偰摿庩側忬嫷偱偼柍偔丄椺偊偽擔杮岅娐嫬偺応崌偵堎帤懱僙儗僋僞(IVS)傗惓婯壔偱忣曬偑楎壔偟側偄CJK屳姺娍帤傪 婎杮暥帤 + Standard Variant (VS1乣3) 偱昞尰偡傞忬嫷傕娷傫偱偄傞.
偙偙偱忋婰偺傛偆偵Unicode偵偍偗傞1暥帤偺奣擮傪傛傝惓妋偵埖偍偆偲偡傞儔僀僽儔儕側傝儈僪儖僂僃傾偑懚嵼偟偨偲偡傞. 偙傟偵懳偟慻傒崌傢偣偰巊梡偝傟傞丄暥帤偲僐乕僪億僀儞僩傪摍壙偲偟偰偟偐僒億乕僩偟側偄Unicode偵懳墳偟偨儔僀僽儔儕側傝儈僪儖僂僃傾傕懚嵼偡傞傕偺偲峫偊傞.
偙偙偱栤戣偵側傞偺偼椉幰偺暥帤偺夝庍偑堎側傞帠偱丄椺偊偽慜幰偱擖椡傪僒僯僞僀僘偟偰屻幰偵棳偡帠傪峫偊傞偲丄愭偺儈僪儖僂僃傾偱堎側傞暥帤偲偟偰埖傢傟偨傕偺偑丄屻偺儈僪儖僂僃傾偱偼扨堦偺僐乕僪億僀儞僩偺傒偟偐嶲徠偝傟側偄堊偵僄僗働乕僾偲敾抐偝傟傞働乕僗偱丄偙傟偼廫擇暘偵僙僉儏儕僥傿儂乕儖懌傝摼傞帠偵側傞 (愭偵彂偄偨儀儖僐乕僪偺僄僗働乕僾偺椺傪嶲徠)
柍榑僄僗働乕僾偺屻傠偵偼扨堦偱偼昞帵晄擻側寢崌暥帤楍偑懕偔堊埨堈側埆梡偼擄偟偄偲巚傢傟傞偑丄偙傟傜傪偳偺傛偆偵埖偆偐偼嵟廔揑偵偼儈僪儖僂僃傾側傝僶僀僷僗憌偱偁傞僌儖乕僗僋儕僾僩偺巇條偱偁傝丄暥帤偺擣幆偑堎側傞帠偐傜敪惗偡傞晄妋掕梫場帺懱偼寛偟偰彍嫀弌棃傞傕偺偱偼柍偄.
嵟埆側偺偼偙偺栤戣偑Unicode傪埖偆応崌偵 婎杮暥帤+寢崌暥帤*n 傪埖偆偐丄僐乕僪億僀儞僩偺傒傪埖偆偐偺忦審偵偮偄偰攔懠揑偵偟偐惉棫偟側偄揰偵偁傞. 椺偊偽擖椡偺僒僯僞僀僘傪僐乕僪億僀儞僩扨埵偱埖偆応崌丄惓忢側 婎杮暥帤+寢崌暥帤*n 偺僔乕働儞僗偺帩偮忣曬傕攋夡偝傟偰偟傑偆.
偙偺慖戰偵偍偄偰偼忢偵偳偪傜偐傪慖戰偣偹偽側傜偢丄傑偨尰忬偵偍偄偰偼杦偳偺応崌Unicode巇條傪姰慡偵僒億乕僩偟偨僜僼僩偺曽偑埑搢揑偵彮側偄帠傪峫偊傞偲丄尰幚揑偵偼僐乕僪億僀儞僩傪暥帤扨埵偲偟偰埖偆慖戰偼寛偟偰幪偰傞帠偼弌棃側偄. 傛偭偰Unicode僐儞僜乕僔傾儉偺採彞偡傞傛偆側傛傝峀斖側Unicode僒億乕僩偵偮偄偰偼彮側偔偲傕僆僾僔儑儞偲偟偰偺慖戰偺傒偱丄寛偟偰僨僼僅儖僩摦嶌偲偟偰嵦梡偡傞栿偵偼偄偐側偄帠偵側傞.
柍榑幚嵺偵偼忋婰偺栤戣偵娭學偟側偄暘栰偺僜僼僩傕戝懡悢偁傞丄偟偐偟堦曽偱忋婰偑塭嬁偡傞暘栰傕忢偵懚嵼偟偰偍傝. 寢壥偲偟偰忢偵乽暘抐乿偑夝徚晄擻側宍偱墶偨傢傝丄偙傟傜偵偍偄偰Unicode偺埖偄偑摑堦偝傟傞帠偼寛偟偰柍偄帠傪帵偟偰偄傞.
...偲傑偀丄偙傟偑昞戣偺乽偲傫偱傕側偄帠乿偵憡摉偡傞榖偵側傞丄彫偝側栤戣偼僙僉儏儕僥傿忋偺寽擮偑偁傞帠丄戝偒側栤戣偼偦傟偑Unicode偺崻姴偺巇條偵怘偄崬傫偱偍傝丄埨掕偟偨丒崻杮揑側夝寛嶔偑 (彮側偔偲傕尰帪揰偱偺Unicode巇條偱偼(仸2)) 懚嵼偟側偄帠 偲側傞.
柍榑偙傟偼帺暘偺瀀桱埥偄偼巚偄堘偄偱偁傞壜擻惈傕偁傞偑丄堦墳偺峫嶡偺儊儌偲偟偰偙偙偵婰嵹偟偰偍偙偆偲巚偆;-)
---------------
仸1) 奼挘彂婰慺僋儔僗僞偵偮偄偰偼妋偐偵儐乕僓乕偺擣幆偡傞1暥帤偺巜昗偲偟偰偼椙偄偺偩偑丄斀柺敿妏僇僫 + 戺揰丒敿戺揰偑1暥帤偲尒側偝傟傞摍偺嫇摦傪帵偡堊丄偙傟偑乽曇廤乿偲偄偭偨僼僃乕僘偵偍偄偰揔偟偰偄傞偐偼堦峫偺梋抧偑偁傞:-<
仸2) 巇條偵庤傪擖傟傞尷傝懳墳嶔偼柍偄儚働偱偼柍偄丄弮悎側僨乕僞僽儘僽偲偟偰偺娤揰偺傒偱暥帤僐乕僪偑掕媊偝傟偰偄傞帠偑栤戣偱偁傝丄偙傟偑僐儅儞僪+僨乕僞偺崿嵼娐嫬偱偺栤戣傪堷偒婲偙偡儚働偱丄僐乕僪懱宯埥偄偼惓婯壔偺曄宍偺堦宍懺偲偟偰ASCII偺愨懳惈偺傒扴曐偝傟偰偄傟偽椙偄偲傕尵偊傞. 偨偩婛偵ASCII偺捠忢暥帤偲寢崌偡傞暥帤傕懚嵼偟丄峏偵偼僩儖僐岅偺'i'偺栤戣側偳傕偁傞偺偱廋惓偼擄偟偄偲巚傢傟傞. 僒僽僙僢僩傪掕媊偡傞側傜梋抧傕偁傞偑丄偦傟埲奜偱偼偣偄偤偄忳曕儔僀儞偲偟偰崌惉暥帤偑妱傝摉偰傜傟偰偄側偄ASCII偺婰崋偵偮偄偰偺 (彨棃揑側奼挘偱傕塭嬁偝傟側偄) 愨懳惈傪扴曐偡傞埵偑尷奅偐傕偟傟側偄 (扨弮側僄僗働乕僾側傜婰崋偺傒偱椙偄偑暋嶨側峔憿傪婰弎偡傞応崌偵偼ASCII暥帤慡堟偑扴曐偝傟偰偄側偄偲幚梡揑偱偼柍偄偑):-<
...幚偼4擭慜偵傗偭偨榖丄僱僞偵偡傞偲尵偭偰偄側偑傜丄愭擔桭恖偲偺榖戣偵忋偑傞傑偱偡偭偐傝朰傟偰偄偨orz
偲偄偆帠偱偙傫側嬶崌
廗嶌側偺偱僾儘僌儔儉偲偟偰偺僀儞僞乕僼僃僀僗摍偼惍旛偟偰偄側偄偑丄夋柺傪尒偰偺捠傝僔儞僞僢僋僗僴僀儔僀僩傗丄夋柺暆偱偺愜傝曉偟丄壜曄僺僢僠僼僅儞僩傊偺懳墳 (t1.cpp撪偺WM_CREATE偱僼僅儞僩巜掕偟偰偄傞強傪曄峏偡傟偽僥僗僩壜擻) 摍帠慜偵憐掕偟偰偄側偄偲傗傗偙偟偔側傞晹暘偵偮偄偰偼堦捠傝巇崬傒偼姰椆偟偰偄傞偲巚偆...偱傕憡曄傢傜偢unicode娐嫬(仸1)偱偼柍偄偺偱Shift_JIS偱偺幚憰(嬯徫) 幚嵺偼偙傟傪儀乕僗偵梡搑偵傛傝擏晅偗偟偰峴偔僇儞僕.
僐乕僪偺婯柾偼7000峴掱搙偩偑敿暘偼斈梡偺儔僀僽儔儕側傫偱丄幚幙揑偵偼3000峴偪傚偭偲丄偨偩媣偟傇傝偵尒偨傜壗傪傗偭偰偄傞偐僒僢僷儕偱峔憿傪巚偄弌偡偺偵嶌偭偨恖娫偑3擔掱偐偐偭偰偄傞偺偱丄梋傝僒儞僾儖偲偟偰偼椙偔側偄偐傕偟傟側偄orz
摿偵栚揑偼柍偄偺偩偑丄嵟掅尷偺僥僉僗僩僄僨傿僞傪嶌傞応崌偺僐僗僩偺尒愊傕傝偑梸偟偐偭偨偲偄偆強丄幚嵺嶌偭偨帠柍偐偭偨偟(徫).摉帪偙偙傑偱慻傓偺偵妱偲僈僠偱傗偭偰1儢寧庛偐偐偭偨婰壇偑偁傞偺偱丄夛幮偱傗傞側傜傑偀嵟掅3儢寧偲偄偭偨強丄偙偙偐傜婡擻傪憹傗偡偲梡搑偵傕埶傞偗偳6儢寧掱搙偐側偀傒偨偄側. 幚嵺偼僛儘偐傜偺僗僞乕僩側偺偱丄偐偐偭偨帪娫偺敿暘偼僨乕僞儌僨儖偲API偺梡朄偺帋峴嶖岆偑儊僀儞偱偼偁傞偺偩偗偳. 偪側傒偵撪晹揑偵偼夋柺嵗昗偱僇乕僜儖傪曐帩偟偰昁梫偵側偭偰偐傜惓婯壔偟偰偄傞傛偆側嬶崌丄怓乆帋偟偨偗偳夋柺偺僗僋儘乕儖偲偐傪峫偊偨応崌偵偙傟偑堦斣埖偄堈偐偭偨僇儞僕.
側偍崱夞up偡傞偵偁偨偭偰undo峔憿傪巄掕幚憰偺儕僗僩峔憿偐傜丄屌掕僒僀僘偺僶僢僼傽偵儕儞僌揑偵媗傔崬傫偱峴偔宍偵曄峏偟偨. 僥僉僗僩僄僨傿僞偺傛偆側宍幃側傜儕僗僩傗僼傽僀儖偵儅僢僾壜擻側僗僩儕乕儉偱偺(傎傏)柍惂尷undo偺曽偑椙偄偺偩偑丄晹昳偲偟偰慻傒崬傓応崌偵偼偙偪傜偺曽偑儊儌儕偺徚旓傪埨掕偟偰尒愊傕傟傞偺偱椙偄偺偱偼側偄偐偲巚偆 (ring_undo.cpp撪丄偛偔彫偝側僐乕僪偩偗偳偙偆偄偆偪傚偭偲婥偺棙偄偨僐乕僪曅偼慻傫偱偄偰暿偺妝偟偝偑偁傞僇儞僕).
傑乕屻偼敿暘偼IMM偲僇儗僢僩娭學偺API偺僒儞僾儖偵側偭偰偄傞僇儞僕偐傕偟傟側偄(嬯徫)
幚憰偵偮偄偰偼彂偒巒傔傞偲怓乆偁傞偺偩偑丄嵟嬤偼擔婰傕彂偄偰偄側偄帠偐傜敾傞傛偆偵丄壗偐傪尵偄偨偄偲偄偆姶妎偑傎傏奆柍側偺偱丄偙偺暥復傪彂偄偰偄傞偺傕寢峔柺搢偩偭偨傝偲偐側傝懯栚懯栚(sigh
傑乕偦傫側嬶崌偱丄僥僉僗僩僄僨傿僞傕埨捈側幚憰側傜寛偟偰寉偔偼柍偄傕偺偺丄偦傟掱擄偟偔傕柍偄偲偄偭偨掱搙偺榖.
# 傑偀丄尰忬偺幚嵺帺暘偺梡搑偲偟偰偼帺嶌偱巊偭偰偄傞晅獬僜僼僩(徫)偺撪憼僄僨傿僞傗丄帺嶌尵岅偺僐儅儞僪儔僀儞曗彆梡偺慻傒崬傒僄僨傿僞埵偟偐巊偄強傕柍偄偺偱丄僾儘僌儔儉偲偟偰偼偄偠偭偰偄偰偦偙偦偙柺敀偄傕偺偺丄懠偵傗傞帠偲斾傋傞偰偦傟掱儌僠儀乕僔儑儞偼弌偰偙側偄強丄傑乕偦傫側帠尵偭偰偄傞傛偆偠傖懯栚側偺偐傕偟傟側偄偗偳(嬯徫)
---------------
仸1) unicode傕僒儘僎乕僩儁傾掱搙傑偱偼椙偄偺偩偗偳丄恀柺栚偵懳墳偡傞偲埆柌偺傛偆側寢崌暥帤偺巇條 (巇條忋弴晄摨偱柍惂尷偵寢崌壜擻) 偲偐丄峏偵偦偺摍壙惈偺栤戣偲偐傪峫偊傞偲Shift_JIS側傫偐斾妑偵側傜側偄埵僌僟僌僟偩偭偨傝偡傞偺偼壗偲偐側傜側偄傕偺偐:-< (摍壙惈偵偮偄偰偼CJK屳姺娍帤側傫偐傕峫椂偡傞偲撈棫偟偨僐乕僪億僀儞僩偵壛偊丄堎帤懱僙儗僋僞(IVS)偲standard variant(VS1乣VS3)偺塭嬁偱摨偠暥帤偵偮偄偰暋悢偺昞尰偑壜擻偩偭偨傝偲嵟嬤偼峏偵埆壔偟偰偄傞偟)
暥帤斾妑偺casefold(仸2)側傫偐傕巇條偵崌傢偣傛偆偲偡傞偲UCD傪曄姺偟偨傕偺傪慻傒崬傓昁梫偑偁偭偨傝偲丄朷傓埲忋偵僶僀僫儕僒僀僘偑旍戝壔偡傞傢丄儊儞僥僫儞僗偱偼UCD偺僶乕僕儑儞偑栤戣偵側偭偨傝偡傞傢丄嫇嬪暥帤偺挿偝傗僀儞僨僢僋僗埵抲傕曄傢傞傢 (1暥帤偑暋悢暥帤偵側傞奼戝曄姺偩偗側傜傑偩儅僔偩偑丄儕僈僠儍偲偐偑棈傓応崌偼1暥帤偑0.5暥帤摍偵側傞働乕僗傕偁傝拞娫堦抳忬懺傪偳偆張棟偡傞傋偒偐偼旕忢偵擸傑偟偄) 惓婯摍壙惈偱偼婰崋偺弴彉偑僜乕僩偝傟傞帠偱僀儞僨僢僋僗偺慜屻娭學偡傜曄傢偭偰偔傞傢偱丄傕偆壗偲傕壗偲傕X-< (偦傟偱傕斾妑偱UCA傑偱僒億乕僩偟側偒傖側傜傫僜僼僩偵斾傋傟偽傑偩儅僔側傫偩傠偆偗偳)
仸2) 梋択偩偑Unicode偺casefold偲惓婯壔晹暘偱偼屆戙僊儕僔儍暥帤偺壓晅偒i(僀僆僞)偺傒傪僒億乕僩偡傞堊乽偩偗乿偵梋暘側張棟偑昁梫偵側傞屄強偑偁傞丄擔杮岅寳偺帺暘側傫偐偐傜偡傟偽暿偵偦偺埵徣偄偰傕椙偄傫偠傖側偄偲巚偭偨傝偡傞偺偩偑丄(帺暘偼偳乕偱傕椙偄偑) 帪偵擔杮恖偑媽帤懱側傫偐偵峉傞傛偆偵屆戙僊儕僔儍暥帤偭偰偺偼儓乕儘僢僷尵岅寳偵偍偗傞儘儅儞側偺偐偹偉丄側傫偰巚偭偰傒偨傝. 傑乕暥帤僐乕僪偺栤戣偼僐儞僺儏乕僞忋偱偺懨摉側昞尰偺柾嶕偲偄偆傛傝偼擩傠丄偦傟偧傟偺尵岅寳偺僄僑偺搳塭偺栤戣側偺偱偙偙傑偱僌僟僌僟偵側傞偺偩傠偆偗偳sigh.
仸3) 偲偄偆偐Win8偱寲揱偝傟偰偄偨堎帤懱僙儗僋僞傪娷傔偨unicode偺寢崌暥帤偺巇條傗偦傟偲棈傔偨惓婯摍壙惈傗full casefolding偺巇條偭偰暥帤楍傪扨側傞夠 (blob) 偲偟偰埖偆応崌偼栤戣柍偄傕偺偺丄偦偙偐傜摜傒崬傫偱晹暘暥帤楍傗偦偺曇廤丒専嶕 (偙偺夁掱偱楢懕偟偨僶僀僩楍偑堦夠偺暥帤偵側傞偲偄偆峫偊曽偡傜濨枂偵側傞) 偲偄偭偨榖傪崿偤崬傓偲偳偆峫偊偰傕攋抅偟偰偄傞巇條偲偟偐巚偊側偄偟丄傑偨偙傟傪儐乕僓乕偵偼摟夁揑偵1暥帤偵尒偣傛偆偲偄偆峫偊曽偼屻乆偺帪戙傑偱峫偊傞偲偲傫偱傕側偄晧嵚偵偟偐側傜側偄傛偆側丄峊偊栚偵尵偭偰傕摢偑偍偐偟偄偲偟偐巚偊側偄偺偩偗偳偹偉X-<
---------------
(2016/10/21捛婰)
仸埲壓偺撪梕偼帺暘偑幚嵼偺奺尵岅寳偵偮偄偰偺廫暘側抦幆傪帩偨側偄堊丄僐儞僺儏乕僞忋偺婯奿偺傒偐傜椶悇偟偨撪梕偱丄晄妋偐側椶悇偑娷傑傟傑偡.
愭擔偺Unicode偵娭偡傞嬸抯偵棈傫偱丄桭恖偐傜乽崌惉嵪傒暥帤偺傒偲偟偰懠偼柍帇偠傖懯栚側偺?乿偲偄偆巜揈偑 偁偭偨偺偱捛婰.
傑偢崌惉暥帤偩偗偱傕慡偰偺暥帤偑埖偊傞偐偵偮偄偰偩偑丄妋偐偵擔杮岅偺戺揰丒敿戺揰偺傛偆側傕偺偼懳墳偡傞崌惉嵪傒偺暥帤傕廂榐偝傟偰偄傞傕偺偺丄偞偭偔傝挱傔偨偩偗偱偼偁傞偺偩偑丄椺偊偽僨乕償傽僫乕僈儕乕暥帤 (僀儞僪,僸儞僪僁乕岅?) 偵偮偄偰偼儕儞僋愭偺僉乕儃乕僪儗僀傾僂僩傕峫椂偡傞偲unicode偺捠忢暥帤+寢崌暥帤偺傒偱偟偐埖偊側偄傛偆偵尒偊丄幚嵺偵偦傟偑昗弨偱偁傞壜擻惈傕崅偄.
傑偨Unicode偱偼壜擻側尷傝崌惉嵪傒暥帤偱昞尰偡傞(仸1)宍幃 (NFC,NFKC惓婯壔) 傕掕媊偝傟偰偄傞偑丄偙傟偵偮偄偰傕梙傜偓偑偁傝丄椺偊偽僿僽儔僀岅偺崌惉暥帤偺U+FB38 (טּ) 偼U+05D8 U+05BC (טּ)偵暘夝偝傟傞偑丄惓婯崌惉偺椺奜暥帤偵側偭偰偍傝丄NFC,NFKC惓婯壔傪捠偟偰傕捠忢暥帤+寢崌暥帤偺U+05D8 U+05BC偺傑傑偱丄U+FB38偵偼栠傜側偄偺偱丄偙偆偄偭偨応崌偵傕崌惉嵪傒暥帤傪慜採偲偡傞偺偼嬌傔偰婋尟側壜擻惈偑偁傞偺偱偼偲悇應偡傞.
偲傑偀偙傫側嬶崌丄柍榑忋婰偼寢崌暥帤偩偗偵尷掕偡傞応崌偺僌僟僌僟偱偁偭偰Unicode偺帩偮埖偄擄偝偺堦抂偺傒丄専嶕傗晹暘堦抳偵偮偄偰偼寢崌暥帤埲奜偵傕儕僈僠儍(崌帤)偺摍壙惈偑峏側傞栤戣偲偟偰娷傑傟傛傝榖傪暋嶨偵偡傞僇儞僕X-<
# 忋婰僌僟僌僟偵偮偄偰偼捈岎偟偨夝偼柍偄壜擻惈傕偁傞丄偲偄偆偺傕偐偮偰Unicode僐儞僜乕僔傾儉偺採彞偟偨Unicode懳墳偺惓婯昞尰巇條偱偼casefolding傪巊梡偟偨堦抳偵偮偄偰full casefolding (暥帤偺1:1懳墳偑曵傟壜曄偵側傞) 傪僒億乕僩偡傞帠傪梫媮偟偰偄偨偑丄偙偺撪梕偼偦偺屻庢傝壓偘(Retracted)傜傟偰偄傞柾條丄惓婯摍壙惈偵偮偄偰傕幚嵺偵偼擄偟偄偐傜僥僉僗僩傪NFD偐NFKD偱暘夝偟偰丄惓婯壔偵栤戣柍偄僷僞乕儞傪巊偆偲壗偲偐側傞傛(堄栿)傒偨偄側彂偒曽偑偝傟偰偄偰壗偲傕壗偲傕:-<
仸1) 惓妋偵偼惓婯崌惉傪忋婰偺傛偆側昞尰偱昞偡偺偼傗傗岅暰偑偁傝丄惓婯壔偺杮棃偺栚揑偼Unicode昞尰偺乽堦堄惈乿傪曐徹偡傞帠偵偁傝丄傑偨僶乕僕儑儞偵傛傞塭嬁偱捛壛偺崌惉嵪傒偺暥帤偑捛壛偝傟偨応崌偵偼夁嫀偺屳姺傑偱娷傔偨堦堄惈偺曽偑桪愭偝傟傞偺偱丄昁偢偟傕壜擻側尷傝崌惉嵪傒暥帤偱昞尰偝傟傞偲偼尷傜側偄帠傪拲婰偟偰偍偔 (嬶懱揑偵偼惓婯壔偑掕傔傜傟偨偺偑Unicode 3.0.0偱偁傝偙傟埲崀偵捛壛偝傟偨崌惉嵪傒暥帤偼崌惉彍奜偲側傞).
側偍Unicode惓婯壔偵偮偄偰擔杮岅寳偵尷掕偡傞偲CJK屳姺暥帤 (擔杮岅寳偱偼堦晹偺媽帤懱) 偺帤懱偑幐傢傟傞栤戣偑偁傞. 偙傟傪旔偗傞応崌CJK屳姺暥帤傪Standard Variant偱掕媊偝傟傞捠忢暥帤+VS1乣3(U+FF00乣U+FF02)偵曄姺偡傞昁梫偑偁傞. 扐偟偙傟偲偼暿偵摨偠帤懱偺暥帤偑堎帤懱僙儗僋僞(IVS)偵傕掕媊偝傟偰偄傞応崌偑偁傞偺偱丄栤戣偼旕忢偵傗傗偙偟偔側偭偰偄傞丄柍榑摨偠帤懱偱偁傞敜偺 婎杮暥帤+VS1乣3 偲 婎杮暥帤+IVS偼Unicode偺斾妑忋堎側傞傕偺偲偟偰敾掕偝傟傞丄IVS偺曽偑堦斒偵僇僶乕斖埻偼峀偄斀柺丄CJK屳姺娍帤偵懳偡傞曄姺偑尩枾偵掕媊偝傟偰偄傞偺偼Standard Variant偱偁傞VS1乣3偺曽偺傒偲側傞X-<
偄偢傟偵偣傛尰帪揰偱偼Unicode偺惓婯壔偼堦堄惈傪曐徹偡傞堊偺撪晹昞尰偵偮偄偰偺傒揔梡偟丄儅僗僞乕僨乕僞偵揔梡偡傞傋偒傕偺偱偼柍偄傕偺偲巚傢傟傞. 側偍偙偺椶偺摍抣惈偺斾妑傪儐乕僓乕(僾儘僌儔儅)偵懳偟偰埫栙偵峴偆偺偑椙偄偐偵偮偄偰偼媍榑偺梋抧偑偁傞帠傕拲婰偟偰偍偔丄柧帵揑側棙梡偼儐乕僓乕偵Unicode偺惓婯壔偺嬶懱揑側曄姺傑偱娷傔偨惓妋側抦幆傪梫媮偟丄幚幙揑偵偼旕忢偵尩偟偄斀柺丄埫栙偺曄姺傪敽偆尵岅偵偼Mac偺Swift摍偑偁傞偑丄偙傟偲擔杮岅偺斾妑偵偍偗傞崿棎偼専嶕偟偰傒傟偽婔偮傕儕僗僩傾僢僾偝傟傞:-<
側偍惓婯壔偵傛傝Unicode偺摍抣惈偼扴曐偝傟傞偑丄偙傟偵懳偟峏偵戝彫斾妑傪峴偆傕偺偲偟偰UCA偲偄偆偺傕掕媊偝傟偰偄傞丄扐偟幚嵺偵偼戝彫娭學偼帿彂弴彉摍丄尵岅寳偵嬌傔偰枾愙偵寢傃偮偄偨傕偺偱偁傝丄偙偺掕媊偼朿戝偵側傞 (堦墳ICU儔僀僽儔儕偲偟偰採嫙偟偰偄傞僾儘僕僃僋僩偼懚嵼偡傞). 幚嵺偙偺曈偺朿戝側掕媊儀乕僗偺張棟偑柺搢偩偭偨偺偱UCA偺婎杮僥乕僽儖偵娭偡傞幚憰傑偱偼傗偭偰傒偨傕偺偺 (偙傟偼栶偵棫偨側偄) 尵岅寳偵傛傞僇僗僞儅僀僘傑偱娷傔偨幚憰偵偮偄偰偼抐擮偟偨僇儞僕orz
偪側傒偵塱懕惈傪敽傢側偄扨弮側Unicode偺儘働乕儖傪壛枴偟偨戝彫斾妑偱偁傟偽昗弨儔僀僽儔儕偺wcscoll(), wcsxfrm()偱壜擻丄幚嵺偳偺掱搙偺惓妋偝傪帩偮偐偼儔僀僽儔儕偺幚憰埶懚偲側傞偑...(側偍wcsxfrm偺寢壥偼崅懍壔傪峫椂偟偨暵偠偨傾僾儕撪偺帠慜寁嶼梡偱塱懕壔傪曐徹偝傟偨傕偺偱偼柍偄(敜)側偺偱拲堄) VC++娐嫬偱偼偙傟偼API偺LCMapString偵LCMAP_SORTKEY傪巜掕偟偨傕偺偲偟偰幚憰偝傟偰偍傝丄僜乕僩寢壥偼僄僋僗僾儘乕儔偺僼傽僀儖柤偺弴彉偲傎傏摨條偺寢壥偵側傞 (慡偰偺働乕僗偱姰慡偵堦抳偡傞偐偼枹妋擣).
...傑偀UCA偱傕摨堦僶乕僕儑儞+尵岅寳偱偺僜乕僩僉乕偼屳姺惈傪曐偰傞傕偺偺丄僶乕僕儑儞偑曄傢傞偲僉乕偺屳姺惈偼柍偄栿偩偑(嬯徫)
憡曄傢傜偢Thompson NFA丄婔偮偐僥僗僩傪夞偟偰偄偨強 worst case僥僗僩偺拞偱丄懳徾暥帤楍丄惓婯昞尰忬懺悢嫟偵n抜奒偵憹壛偡傞傕偺偱丄棟榑忋 O(n^2) 偱姰椆偡傋偒屄強偑 O(n^3) 偐偐偭偰偟傑偭偰偄偨orz
岾偄怱摉偨傝偼偁偭偨偺偱丄偦偺晹暘傪廋惓偟偰姰椆. 尨場偼 Thompson NFA偺応崌暋悢偺僗儗僢僪 (幚峴扨埵) 偑暥帤徚旓扨埵偺僯儌僯僢僋(儕僥儔儖, 暥帤僙僢僩, 儅僢僠姰椆)偱摨婜揑偵幚峴偝傟丄偙偺奺幚峴扨埵偱婛偵僗働僕儏乕儖偝傟偰偄傞僗儗僢僪偲廳暋偡傞忬懺傪帩偮僗儗僢僪傪婞媝偡傞帠偱崅懍側張棟傪幚尰偟偰偄傞偑丄摨婜扨埵偺僯儌僯僢僋偩偗偱柍偔丄摨婜扨埵偵摓払偡傞傑偱偺僯儌僯僢僋偵傕婛偵幚峴偟偨宱楬偱偁傟偽婞媝偡傞張棟偑昁梫偩偭偨偺傪峴偭偰偄側偐偭偨偲偄偆榖.
偙傟偱傔偱偨偔 O(n^2) 偱姰椆偟丄偳偺傛偆側惓婯昞尰偵偮偄偰傕僉儍僢僔儏岠棪摍傪彍偄偰擖椡丄僷僞乕儞偺偦傟偧傟偵偮偄偰 O(n) 偺埨掕惈傪妋曐弌棃傞帠偵側傞. 偲傑偀偙偙傑偱偼椙偄偺偩偑丄慡偰偺僯儌僯僢僋傪廳暋専弌偺懳徾偲偡傞帠偐傜丄偦傟掱暋嶨側徠崌張棟偼 (懍搙揑偵) 峴偊側偄帠偵側傝丄寢嬊僼儔僌偺傒偲偟偰丄桳尷斀暅 {m,n} 偵偮偄偰偼慡偰揥奐張棟偟丄奺斀暅偑慡偰堎側傞忬懺偱偁傞帠傪曐徹偟側偗傟偽側傜側偔側偭偨.
偮傑傝斀暅夞悢偵偮偄偰偼偐側傝尩偟偄惂尷傪偐偗傞昁梫偑偁傞偲偄偆帠偱丄懠偺僄儞僕儞偱偼戝掞埖偊傞65536夞掱搙偱偡傜尩偟偄忬嫷偱彮乆摢偑捝偄. 擸傫偩枛偵Google偺Re2偼偳偺傛偆偵夝徚偟偰偄傞偺偐偲挷傋偰傒偨強丄Re2偱偼扨弮偵斀暅夞悢傪1000夞偵惂尷偟偰偄傞偩偗偩偭偨傝orz (仸1)
傑偀丄奺僯儌僯僢僋偱偺僗儗僢僪偺摨堦徠崌傪暋嶨側張棟偵偟側偄帠偵偼偙偺栤戣偼夝寛弌棃偦偆偵柍偐偭偨偺偱丄帺慜偺傕偺偱傕忋尷傪挻偊偨斀暅偼僐儞僷僀儖僄儔乕偵偡傞宍偵偟偰偟傑偭偨 (夞悢巜掕偺偁傞斀暅偺傒偱偁傞偺偱丄*,+摍偵偼偙偺惂尷偼摉偰偼傑傜側偄) 慜弎偺 O(n^3) 偺僐乕僪偱偼偙偺忬懺嵎傪偦傟掱偺僐僗僩偱偼柍偔嬫暿弌棃傞偺偩偑丄偳偺傛偆側 worst case 偱偁偭偰傕儕僯傾側張棟傪曐徹偡傞曽偑儊儕僢僩偑戝偒偄偲敾抐偟偨堊 :-<
仸1) 傑偀幚嵺偵偼悢1000掱搙傑偱偺夞悢巜掕偑昁梫側惓婯昞尰偼丄帺暘偺宱尡偱偼尵岅張棟宯偺僔儞儃儖挿偵懳偡傞惂尷埵偺傕偺偱丄偦傟偵偟偰傕堦扷柍尷挿偱庢傝崬傫偱偐傜僾儘僌儔儉忋偱惂尷挿傪敾掕偟偰傕椙偄儚働偱丄傑偟偰傗O(n)埨掕惈偺曐徹偲斀暅偵傛傞徚旓儊儌儕偺憹壛 (back track stack) 偑柍偄忬嫷偱偼偦偆偄偆僷僞乕儞傪巊梡偟偰傕壗偺儁僫儖僥傿傕柍偄偺傕帠幚 (巊梡偡傞惓婯昞尰僄儞僕儞偺惈幙偵埶懚偟丄斈梡惈偵偼寚偗傞偺偑擄揰偩偑)
---------------
忋婰偺榖偼奺榑偱偼偁傞偑丄愭擔偺僗儗僢僪偺忬懺慠傝丄Thompson NFA偺巬姞傝偼尰嵼偺惓婯昞尰偺忬懺偲偦傟乽埲崀乿偺儅僢僠寢壥偼丄偦傟乽埲慜乿偺儅僢僠儞僌宱楬偵埶懚偟側偄丄偲偄偆榖傪戝慜採偲偟偰偄傞帠偵側傞. 偙傟偑偦偺傑傑屻曽嶲徠傗揥奐傪敽傢側偄桳尷斀暅(仸2)偑巊偊側偄棟桼偱偁傝 (摉慠忦審暘婒傗僐乕儖僶僢僋偵傛傞張棟偺曄峏摍偺幚憰傕晄壜) 埫栙揑偵偙偺傾儖僑儕僘儉偵壽偣傜傟偨惂尷偲偄偆榖偵側偭偰偄傞.
幚嵺忋婰O(n^3)偺僐乕僪偱僌儖乕僾傑偱僗儗僢僪偺廳暋専弌懳徾偵偡傞偲丄晄梡堄側()傪巊梡偟偨応崌偵1夞偺徠崌偱悢昩乣悢暘掱搙偼偐偐傞忬懺悢偺敋敪傪敽偭偨惓婯昞尰傕敪惗偝偣傞帠偑壜擻偵側偭偰偟傑偆. 偙偺傾儖僑儕僘儉偑幚嵺偵偼埫栙揑側徣棯傪敽偆傕偺偱偁傝丄僶僢僋僩儔僢僋宆偱扵嶕偝傟傞慡偰偺働乕僗傪曪桳偡傞傕偺偱偼柍偄偲偄偆偺偼幚偵嫽枴怺偄榖偩偲巚偭偰傒偨傝.
傑偀丄偦乕偡傞偲丄Re2敪昞摉弶偺 乽Thompson NFA偲偄偆桪傟偨曽朄偑偁傞偵傕娭傢傜偢丄back tracking偱偺幚憰偽偐傝偱丄偦傟偭偰偳乕側傫偩?乿 傒偨偄側昞尰偼傗傗堦曽岦揑偱偁傝丄傑偨帠徾傪姰慡偵岞惓偵偼昞尰偟偰偄側偄偲偄偆揰偱偼僼僃傾偱傕柍偔丄愵忣揑側昞尰偩側偀丄側傫偰巚偭偰傒偨傝 (柍榑偦偆偄偭偨媍榑偐傜back tracking偑慖戰偝傟偰偒偨儚働偱偼乽柍偄乿帠偼100傕彸抦偱偼偁傞偗傟偳;-)
側偍杦偳偺儅僢僠傪憗婜婞媝壜擻側擔忢揑偵巊梡偡傞傛偆側惓婯昞尰偱偼丄尰忬偺帺慜偺Thompson NFA偺VM宆偺幚憰偼埲慜偙偙偵嵹偣偨node宆偺back tracking傪巊梡偟偨傕偺偲摨掱搙偺懍搙丄尰嵼帺暘偑巊梡偟偰偄傞node宆傪僠儏乕僯儞僌偟偨傕偺偲斾妑偡傞偲1.5攞掱搙抶偔丄傑偨尰嵼帋尡拞偺VM宆偺back tracking幚憰 (堦晹嵟揔壔傪彍偒.net, jdk偺惓婯昞尰偲摨掱搙偺懍搙) 偲斾妑偡傞偲2攞掱搙抶偄僇儞僕. 幚嵺Thompson NFA帺懱偺張棟帺懱丄弶婜壔傗憗婜婞媝偵帄傞傑偱偺張棟偑懡偔丄廳偔側傞孹岦偵偁傝丄Google偺Re2偺懍搙偺払惉偼on the fly偺DFA壔摍傪慻傒崌傢偣偨応崌偺懍搙偱丄go尵岅偱巊傢傟偰偄傞扨弮幚憰偱偼傗偼傝抶偄偲偄偆榖偱偁傞偺偱抳偟曽柍偄晹暘傕偁傞偺偩偑...偆乕傫:-<
仸2) 偙傟偼彮乆暘偐傝擄偄偑丄椺偊偽/a?a{2}/偲偄偆惓婯昞尰偵"aa"傪儅僢僠偝偣傞帠傪峫偊傞. 偙偺応崌偵乽夞悢巜掕儖乕僾偺揥奐傪敽傢側偄偲乿忬懺偼a?偲a{2}偺2屄強偵側傞. 傑偢1暥帤栚偺a傪撉傒崬傫偩帪揰偱偼慖戰巿a?偲a{2}偼偦傟偧傟1暥帤a傪庴偗擖傟傞偑丄師偺a偵恑傓抜奒偱偄偢傟偺忬懺傪懸偪庴偗傞偺傕a{2}(1暥帤栚偐2暥帤栚)偱偁傝丄桪愭偼a?偱1暥帤撉傫偩慖戰巿偵側傞偺偱丄屻懕偺a{2}偱傑偢1暥帤撉傫偩慖戰巿偼婞媝偝傟偰偟傑偆偑丄巆偭偨宱楬偺a{2}偼峏偵2暥帤a傪撉傑側偄偲儅僢僠偟側偄堊丄晄堦抳偲偄偆娫堘偭偨寢壥偵側偭偰偟傑偆. 偙傟傪旔偗傞偵偼夞悢巜掕偑懚嵼偡傞儖乕僾偼慡偰堘偆忬懺偲偟偰擣幆偝傟傞昁梫偑偁傝丄偙傟傪岠棪揑偵幚尰偡傞偵偼夞悢巜掕晹傪慡偰揥奐昞尰偵偡傞昁梫偑弌偰偔傞偲偄偆僇儞僕.
愭擔偺Thompson NFA偺審丄庢傝姼偊偢僗儗僢僪偺摨堦惈斾妑偵偮偄偰丄斀暅夞悢 (柍尷斀暅偼彍偄偨桳尷夞偺斀暅巜掕偑昁梫側傕偺偵尷掕) 偺堘偆傕偺偼暿偺僗儗僢僪偲偟偰埖偆傛偆偵偡傞帠偱夞旔偡傞. 偙偙偱僌儖乕僾忬懺偑堘偆傕偺傕堎側傞僗儗僢僪偲偟偰埖偆傋偒偐丄偲偄偆栤戣偑偁傞偑丄偙傟傪嫋梕偡傞偲斀暅偱晄梡堄偵()偑巊傢傟偨応崌偵婔壗媺悢揑側忬懺偺憹暆偑惗偠偰偟傑偆.
偙偙偱僌儖乕僾偵偮偄偰峫偊傞偲丄偦傕偦傕偺栤戣偼愭峴偡傞僗儗僢僪偑儅僢僠偣偢丄偦傟傛傝掅偄桪愭搙偺摨堦PC偺僗儗僢僪偱婞媝偝傟傞傕偺偑儅僢僠偟偰偟傑偆働乕僗偱偁傝丄惓婯昞尰偺儅僢僠婡擻偑僌儖乕僾忬懺偵埶懚偟偰偄側偄尷傝偼僌儖乕僾儗僕僗僞傪斾妑偟偰丄屄暿偺傕偺偲偟偰埖偆昁梫偼柍偄. 尵偄姺偊傟偽偙偺忬懺偱婞媝偝傟摼傞屻懕偑儅僢僠偡傞応崌偵偼丄愭峴偡傞僗儗僢僪傕儅僢僠偡傞帠傪曐徹偡傟偽椙偔丄偙傟偵柕弬偡傞働乕僗偼 (尰忬憐掕偟偰偄傞惓婯昞尰偺暥朄偱偼) 桳尷夞悢偐偮忋尷偺偁傞斀暅偺傒偲偄偆帠偵側傞.
偙傟偑偦偺傑傑Thompson NFA偺崅懍側幚憰偱偼屻曽嶲徠偑巊偊側偄棟桼(仸1)偱偁傝丄傑偨惓婯昞尰偵婡擻傪捛壛偡傞応崌偵偼忋婰偺惂栺偑忢偵惉棫偡傞傛偆偵拲堄偟側偗傟偽側傜側偄 (偦偆偄偭偨堄枴偱偼僶僢僋僩儔僢僋偱偺幚憰偵斾傋傞偲尷掕偑弌偰偟傑偆).
側偍僆僾僔儑儞(icase巜掕摍)偵偮偄偰傕摨條偺媍榑偑偁傞偑丄堦斒揑側惓婯昞尰暥朄偲偟偰僀儞儔僀儞偱偺僆僾僔儑儞曄峏偑僌儖乕僾奜偵傑偱攇媦偡傞峔暥偼柍偄偺偱丄偙傟偵偮偄偰傕彍奜偟偰椙偄帠偵側傞 (暥朄傪奼挘偟偨応崌偵偼峫椂偑昁梫).
仸1) 椺偊偽僌儖乕僾忬懺偺傒偑堎側傞摨堦偺惓婯昞尰A,B偵偮偄偰 (A|B)C 偲偟偰丄A,B偑嫟偵儅僢僠偡傞応崌偵C傪徠崌偡傞抜奒偱婛偵A宱楬偑儅僢僠偟偰偄傞堊丄摨堦PC偱桪愭搙偺掅偄B偼婞媝偝傟傞丄偙偙偱屻曽嶲徠傪僒億乕僩偟偨応崌偱丄C撪偵屻曽嶲徠偑懚嵼偡傞偲丄A宱楬偼儅僢僠偟側偄偑B宱楬偼儅僢僠偡傞働乕僗偑峫偊傜傟傞偑丄婛偵B宱楬偼婞媝偝傟偰偄傞偺偱丄慡懱偲偟偰儅僢僠偟側偄偲偄偆寢壥偑曉偭偰偟傑偆.
僌儖乕僾忬懺偑堎側傞僗儗僢僪傪堎側傞傕偺偵偡傟偽忋婰偼夝寛偡傞偑丄偙偺応崌偵()傪巊偭偨斀暅偺僱僗僩偼婔壗媺悢揑側忬懺偺敋敪傪彽偔堊丄偦傕偦傕偺Thompson NFA偱偺棙揰偑幐傢傟偰偟傑偆帠偵側傞.
---------------
捈姶揑偵偼偙偺峫偊曽偱椙偄偲偼巚偆偺偩偑丄慡偰偺働乕僗傪鋜傔傞帠偑弌棃偰偄傞偐丄彮乆晄埨偼巆傞 :-<
側偍忋偺峫偊曽偼幚幙揑偵偼桳尷斀暅傪慡偰揥奐偡傞帠偵摍偟偔丄斀暅偺僱僗僩偼偦偺斀暅偺夞悢偺憤忔(儺)暘偩偗偺忬懺偑惗偠傞帠偵側傝丄嵟埆偺働乕僗偱偼忬懺悢敋敪偺儕僗僋傪僛儘偵偼弌棃側偄帠偵傕側傞 (柍榑僶僢僋僩儔僢僋宆偱偼偙偆偄偭偨働乕僗偼峏偵抶偔側傞偺偱Thompson NFA偩偗偺寚揰偱偼柍偄偺偩偑).
傫乕丄姰慡側僶僇僠儑儞偵弌棃側偄強偑巆擮側僇儞僕丄偲偼尵偊夞悢傪巜掕偝傟偨斀暅偩偗偱柍尷儖乕僾偼偙偺栤戣傪娷傑側偄堊丄偦傟掱嬌抂側憹壛偵側傞壜擻惈偼掅偄敜偱偼偁傞偑...
側偍尰忬偺懍搙偼暿搑僶僢僋僩儔僢僋宆偱幚憰&僠儏乕僯儞僌 (堦斒揑側惓婯昞尰僄儞僕儞偲摨掱搙偺懍搙) 偟偨傕偺偲斾傋2攞嫮抶偄僇儞僕. 偦傟偱傕1昩偱悢枩夞偺徠崌偼廫暘壜擻偱偁傞帠丄杦偳偺応崌偵懍搙掅壓偲儊儌儕偺朿戝側徚旓偑敪惗偟側偄帠偱梊應斖埻撪偵張棟偑姰椆偡傞帠傪峫偊傞偲丄慡懱偺懍搙傪棊偲偟偰傕偙偪傜傪巊偆曽偑椙偄働乕僗偲偄偆偺偼懡乆偁傞偺傕帠幚.
幚嵺 (帺暘偼実傢傝偑柍偄偑) 摨堦僾儘僙僗偱懡悢偺僀儞僗僞儞僗偑摦嶌偟丄傑偨奐敪恖嵽傕慖暿偑弌棃側偄傛偆側僄儞僾儔宯偺僒乕僶忋偱摦嶌偡傞傕偺偵偮偄偰偼戝暆偵儕僗僋夞旔偑壜擻偲側傞丄傑偨弨晄摿掕懡悢偺恖娫偑彂偄偨僾儘僌儔儉傪幚峴偡傞僽儔僂僓忋偺僄儞僕儞傗丄埥偄偼僥僉僗僩僄僨傿僞摍僄儞僪儐乕僓乕僒僀僪偵惓婯昞尰傪岞奐偡傞傕偺丄web傾僾儕摍偺惓婯昞尰婡擻傪岞奐偡傞傕偺摍丄儕僗僋傛傝傕埨掕惈傪慖戰偡傋偒屄強偼懡乆懚嵼偡傞堊丄崱屻偺曽恓偲偟偰偼怓乆擸傑偟偄強 :-<
Thompson NFA偺幚憰丄忋庤偔偄偭偨偐偲巚偭偨偺偩偑丄抳柦揑側儈僗傪偟偰偄偨柾條orz
嬶懱揑偵偼堎側傞斀暅夞悢偺摨堦PC(VM忋偺僾儘僌儔儉僇僂儞僞)傪摨堦state偲尒側偟偰偄偨椙偄偐偲偄偆強偱丄摨堦偲尒側偟偰偟傑偭偰偄偨寢壥偲偟偰丄偦偺屻偺徠崌偱僄儔乕偵側傞傕偺偑懚嵼偡傞堊偵丄偦偺屻偺徠崌偱壜擻惈偑偁傝摼傞傕偺傑偱婞媝偟偰偟傑偭偰偄偨偲偄偆僇儞僕.
妱偲愝寁偺崻姴偵娭傢傞屄強偱偁傞偺偱堦扷敀巻偵栠偟偰惍棟偡傞昁梫傕偁傝偦偆偱丄摢偑捝偄:-<
壗偐偙偺強傾儗儖僊乕偱錊杻怾偼懕偔偟 (懡暘栄拵) PC偼夡傟傞偟 (偟偐傕忔傝姺偊梡偵攦偭偰偄偨怴偟偄PC丄屆偄PC偼枹偩寬嵼) 挿塉偱擺屗偑姤悈偟偰廂擺暔偑懯栚偵側傞 (夞暅旓梡偩偗偱10枩墌埲忋) 偲壗偲傕摜傫偩傝廟偭偨傝側僇儞僕X-<
彮乆娫偑嬻偄偨偑丄憡曄傢傜偢惓婯昞尰僄儞僕儞偺幚憰.
庢傝姼偊偢僶僢僋僩儔僢僋 + VM宆偺僄儞僕儞偺僠儏乕僯儞僌偼Java,.NET偺幚憰偲斾妑偟偰丄傎傏慡偰偺働乕僗偱Java傛傝抶偄偑.NET傛傝懍偄偐丄埥偄偼偦偺媡偱Java傛傝懍偄偑.NET傛傝偼抶偄偐偺丄偄偢傟偐偼僐儞僗僞儞僩偵弌偰偄傞強傑偱偼帩偭偰峴偗偨僇儞僕.
偦傕偦傕偑僒儘僎乕僩儁傾摍傪堄幆偟側偄Unicode偵斾傋傞偲丄儅儖僠僶僀僩偺張棟偑偐側傝偺僆乕僶乕僿僢僪偵側偭偰偄傞 (慡懱偺30%掱搙) 偺偱丄傑偀戝懱偙傫側強偐偲偄偆強.
偁偔傑偱惓婯昞尰偺捠忢張棟偺崅懍壔偱偁傞偺偱丄摿掕偺暥帤楍傪娷傑側偄傕偺偼梊傔抏偔偲偄偭偨屄暿張棟偼幚憰偟偰偄側偄. 偙傟傪帋尡揑偵幚憰偟偨強偱偼峴扨埵張棟摍偼偲傕偡傞偲10攞埵崅懍偵側傞偑丄傑偀僐乕僪偑旍戝壔偡傞偺偱丄幚憰偡傞偲偟偰傕崱夞偺僠儏乕僯儞僌偲偼暿偺榖.
戝懱new/malloc傪2夞峴偆偐1夞峴偆偐偩偗偱慡懱偺20%掱搙偺懍搙偵塭嬁偡傞傛偆偵側偭偰偒偰偄傞偺偱丄寁嶼検揑側栤戣偲偟偰偼偦傠偦傠尷奅偐丄偲偄偆強偱傕偁傞:-<
---------------
堦曽Thompson NFA + VM偺峔憿偺幚憰傕姰椆丄傗偼傝寽擮偟偰偄偨捠傝丄傾儖僑儕僘儉揑偵昁偢1暥帤偯偮僗僥僢僾傪愗偭偰徠崌偑昁梫 (傑偲傔偰徠崌偱偒側偄) 側帠傗丄帠慜偺僨乕僞峔憿偑暋嶨偵側傞帠偐傜偺傾儘働乕僔儑儞張棟偺憹壛摍偱丄斀暅偺僱僗僩傪敽傢側偄惓婯昞尰偱偼戝懱僶僢僋僩儔僢僋宆偺2攞掱搙抶偄報徾.
幚嵺 <Thompson NFA偺忋尷徠崌夞悢> = <惓婯昞尰偺僗僥乕僩悢> x <扵嶕暥帤楍偺挿偝> 偼埵抲廳暋傪敽傢側偄偩偗偱棟榑忋偺慡悢専嶕偲摍壙偱偁傞偺偱丄僶僢僋僩儔僢僋宆偱扵嶕埵抲偺廳暋偑敪惗偡傞斀暅偺僱僗僩傪敽偆惓婯昞尰埲奜偱岠棪揑偵張棟偱偒傞偐偳偆偐偼偁偔傑偱摑寁忋偺栤戣偱偟偐柍偄.
扐偟僶僢僋僩儔僢僋宆偱悢暘偐偐傞傛偆側昦揑側惓婯昞尰偵偮偄偰傕慄宍帪娫偱姰椆偡傞堊丄僥僗僩儀儞僠偱偼寁應尷奅埲壓偺0msec傪扏偒弌偟偰偔傟傞曈傝 (堦墳Performance counter偵傛傞0msec埲壓偺慄宍惈傕妋擣嵪) 偼丄埨掕惈偲偟偰偼埆偔側偄. 傑偨斀暅偵偍偄偰傕僶僢僋僩儔僢僋宆偵偁傞傛偆側丄嬌抂側擖椡偵懳偡傞徚旓儊儌儕偺敋敪揑憹壛 (斀暅夞悢偵斾椺偟偨僶僢僋僩儔僢僋僗僞僢僋傪徚旓偡傞) 偼柍偔丄僶僢僋僩儔僢僋宆偵斾傋傗傗僐僗僩偼戝偒偄傕偺偺丄摨掱搙偺僗働乕儖帪娫撪偱偼偁傞堊丄惓婯昞尰帺懱傪儐乕僓乕偵岞奐偡傞傛偆側僜僼僩偱偼偙偪傜偺曽偑朷傑偟偄偲巚傢傟傞.
傑偀堦曽傾儖僑儕僘儉偺尷奅偐傜幚憰偑擄偟偄 or 晄壜擻側婡擻傕偁傝丄帺暘偺幚憰偱傕寢嬊Google偺Re2偲摨條 屻曽嶲徠, 愭撉傒,
屻撉傒, 撈棫晹偼幚憰偟偰偄側偄丄愭撉傒偲屻撉傒偼僨乕僞峔憿偺弶婜僐僗僩偝偊夵慞弌棃傟偽晄壜擻偱偼柍偄偑丄屻曽嶲徠偲撈棫晹偼懡暘晄壜擻偲巚傢傟傞
(偁傞堦揰傪徹柧偱偒傟偽丄屻曽嶲徠偼傗傗峫椂偺梋抧偑偁傞偐傕偟傟側偄偺偩偑(仸1)丄惓捈傑偩尒偊偰偄側偄:-<)
偲傑乕偦傫側嬶崌丄偄偄壛尭朞偒偰偄傞偺偱儌僠儀乕僔儑儞偼抧偺掙側偺偩偑(嬯徫)
Thompson NFA偵偮偄偰偼傕偆彮偟僠儏乕僯儞僌偺梋抧傪専摙偡傞梊掕偱偼偁傞偑丄偦傕偦傕偺嶌惉摦婡偑崅懍側儔僀僽儔儕偱偼柍偔丄懠偺僜僼僩偺奐敪帪偵儊儞僥僫儞僗僐僗僩偑尷傝側偔掅偔尒愊傕傟傞庤寉側儔僀僽儔儕偲偄偆帠側偺偱丄忋婰偺榖偐傜偺僼傿乕僪僶僢僋偼偁傞傕偺偺丄愭偵宖嵹偟偨扨弮側僲乕僪宆傪夵椙偟偰巊偆帠偵側傝偦偆側梊姶;-)
仸1, 2014/6/9捛婰)
屻曽嶲徠傕傗傗暋嶨側張棟傪偡傟偽偄偗傞偐偲巚偭偨偑丄傛偔傛偔峫偊傞偲偳偆傕柍棟偭傐偄. 偲偄偆偺傕偁傞暥帤偵帄傞傑偱偵宱楬A偲B偑偁傝(A偑桪愭)丄A,B偺偳偪傜傕傎傏摍壙偺惓婯昞尰偱偦偺慜傑偱偵堦抳偡傞偑丄僌儖乕僺儞僌摍偑堎側傞応崌偱丄偐偮尰嵼偺偁傞暥帤埲崀偑偦偺屻曽嶲徠偺B偵偺傒堦抳偡傞応崌偵丄A傪徚壔偟偨帪揰偱B偐傜棃偰尰嵼偺暥帤偵帄傞傑偱偺宱楬偼摨堦PC傪帩偮堊婞媝偝傟傞帠偵側傞丄傛偭偰A偑晄堦抳偺応崌偵B偼婛偵姞傝庢傜傟偰偄傞偺偱帋峴弌棃側偄丄偲偄偆嬶崌:-<
惓婯昞尰儔僀僽儔儕偵偮偄偰壖憐儅僔儞(VM)宆偺幚憰傪傗偭偰傒傞丄僐乕僪惗惉晹偼傎傏姰惉丄杮棃偼偙偙偱徯夘偝傟偰偄傞 Thompson NFA (慜夞偺擔婰偵彂偄偨暆桪愭宆偺専嶕) 偺専徹偺堊偩偑丄庢傝姼偊偢婛偵巇忋偑偭偰偄傞僶僢僋僩儔僢僋宆偺徠崌偵偮偄偰丄慜夞偺僲乕僪楢寢宆偺僨乕僞峔憿偲偺僷僼僅乕儅儞僗斾妑偲偟偰幚憰偟偰傒偨.
寢壥偲偟偰偼巚偭偰偄偨掱偱偼柍偔丄偍傛偦10乣30%掱搙偺懍搙岦忋. 峔暥栘偲VM僯儌僯僢僋偺惗惉偑暘棧偝傟偰偄傞偺偱丄摿掕忦審偺傒昁梫側張棟傪徣偔摍偺嵟揔壔偱偍傛偦1.5乣2攞掱搙岦忋偡傞働乕僗傕尒傜傟偨.
VM帺懱偼僗僩儕儞僌僥乕僽儖傪嶲徠偡傞堊丄1夞偺傾僪儗僗娫愙偑巆偭偰偄傞偑丄慜偺傕偺偐傜偦傫側偵偼懍搙偺岦忋偑尒傜傟側偐偭偨帠偐傜丄嵟揔壔傪娷傑側偄惓婯昞尰偑尰偡峔憿偦偺傑傑偱偺徠崌偲偟偰偼丄寑揑側懍搙岦忋偼擄偟偦偆側暤埻婥.
堦晹2攞掱搙偺岦忋偼尒傜傟丄婔偮偐偺僥僗僩働乕僗偱偼晛媦偟偰偄傞 (偦傟掱僠儏乕僯儞僌偝傟偰偄側偄) 惓婯昞尰儔僀僽儔儕偲摨掱搙偐丄堦晹偼偦傟傛傝傕崅懍偵摦嶌偟偰偍傝丄嵟揔壔傪傕偆彮偟媗傔傟偽杴偦偵偍偄偰堦斒揑側儔僀僽儔儕偲摨掱搙偵偼帩偭偰峴偗偦偆偩偑丄僐乕僪帺懱偼憹壛偟偰峴偔偺偱丄杮嬝偱偼柍偄儔僀僽儔儕偵偦偙傑偱庤傪偐偗傞偺偑椙偄偐偼擸傑偟偄強.
惓捈側強丄愝掕僼傽僀儖傗扨弮側屄恖儗儀儖偺僨乕僞僼傽僀儖偺夝愅側傜慜夞偺傕偺偱傕廫暘側婥傕偟偰丄偳乕偵傕傗傞婥偑弌側偄(徫)
Thompson NFA偺曽偼専嶕埵抲偺廳暋偵傛傞僆乕僶乕僿僢僪偼徣偗傞偑丄1暥帤偢偮慖戰巿傪摨婜壔偟側偑傜斀暅偡傞僐僗僩偑僶僢僋僩儔僢僋宆偺張棟傛傝傕廳偄偺偱丄扨弮幚憰偱偼斾妑揑僶僢僋僩儔僢僋偺彮側偄僷僞乕儞偱偼僶僢僋僩儔僢僋宆偺曽偑桳棙偵側傝偦偆側暤埻婥偱偁傞偟...傑偀懡暘傕偆彮偟 (僟儔僟儔偲) 懕偒偦偆側梊姶.
傑乕昞戣偺捠傝
偲偄偆帠偱崱夞慻傫偩偺偼 偙傫側嬶崌 堦墳傎傏僼儖僙僢僩偺幚憰偵側偭偰偄傞;-)
彮乆壣偟偰偄偨偺偲丄偄偄壛尭C/C++偱愝掕僼傽僀儖偺夝愅偱枅夞摨偠傛偆側parse張棟傪彂偔偺偵偆傫偞傝偟偰偄偨偑丄彫偝側僾儘僌儔儉偺応崌偵戝妡偐傝側儔僀僽儔儕傪儕儞僋偡傞偺傕傾儗側偺偱丄嬌椡僐儞僷僋僩側宍偺惓婯昞尰儔僀僽儔儕傪帺嶌偱偒側偄偐偲偄偆帠偱傗偭偰傒偨(仸1)
棙曋惈偲偟偰偼1000峴掱搙偱廂傑偭偰偔傟傞偺偑棟憐側偺偩偑丄婡擻傪峣偭偨廗嶌偱偼堄枴偼柍偄堊丄幚梡偵姮偊傞偩偗偺婡擻傪堦捠傝忔偣偨強丄巆傝偼幹懌揑偵捛壛偱偒偦偆側忬嫷偱丄寢嬊傎傏僼儖僙僢僩偺婡擻傪幚憰偡傞宍偵側傞. 寢壥偼惓婯昞尰偺僐傾偑2100峴丄僗僋儕僾僩揑側憖嶌 (match,sub,split摍) 傪僒億乕僩偡傞儔僢僷乕偑400峴掱搙偲丄婜懸傛傝傕傗傗戝偒傔偵側偭偰偟傑偭偨偺偼擸傑偟偄強偱偼偁傞 (巆擮側偑傜嵟掅尷幚梡偵懴偊傞婡擻偩偗忔偣偰傕寢嬊僐傾偼1300峴掱搙偼偁偭偨)
弌愭偱僱僢僩摍偱偺忣曬廂廤偑弌棃側偄忬嫷偱偁偭偨堊丄幚憰曽幃偼傗傗変棳偵側偭偰偟傑偭偨姶偼偁傞偑(仸2) 乽懎偵乿Traditional 側 NFA偲徧偝傟傞傕偺偱丄婎杮揑偵偼NFA偱憐掕偝傟傞峔憿傪儀乕僗偵丄徠崌偼僶僢僋僩儔僢僋傪巊梡偟偨傕偺. 屻撉傒峔暥 (?<=乣), (?<!乣)偺惂栺偑傗傗尩偟偄帠傪彍偗偽丄堦斒揑側惓婯昞尰偱僒億乕僩偝傟傞婡擻偼杦偳栐梾偟偨僇儞僕丄暥帤僐乕僪偼尰忬偼SJIS / raw僶僀僫儕徠崌偺愗傝懼偊幃 (僀儞儔僀儞僆僾僔儑儞偱晹暘揔梡傕壜擻) 偱僶僀僫儕僼儕乕 + 儅儖僠僗儗僢僪懳墳偲側偭偰偄傞.
幚峴懍搙偼傗傗抶偔丄儊僕儍乕側惓婯昞尰僄儞僕儞偵斾傋 1.5乣3攞掱搙抶偄偲偄偆強偩偑丄扨弮偝傪嵟桪愭偟偰嵟揔壔張棟偼傎傏慡偔偲尵偭偰椙偄掱峴偭偰偄側偄堊丄傑偢堦曕偲偟偰偼丄偙傫側傕偺偐偲偄偆強 (偲偼尵偭偰傕1枩峴偺僜乕僗偵懳偡傞峴扨埵grep偱偼50msec埲壓偱廔傢傞掱搙).
...偲丄傑乕偙傫側嬶崌偱巇忋偑偭偨偺偩偑丄偄偞嶌偭偰傒傞偲側傑偠拞恎傪棟夝偟偰偄傞偺偱丄僶僢僋僩儔僢僋傪巊梡偟偨惓婯昞尰僄儞僕儞偑愽嵼揑偵帩偮僆乕僶乕僿僢僪(仸3)偑婥偵側偭偰巊偆婥偑婲偒側偔側偭偰偟傑偭偨(偊乕
傑乕壗偲傕壗偲傕...娫敳偗側僆僠偑偮偄偰偟傑偭偨儚働偱(嬯徫)
嬿乆傑偱攃埇偟偰偄偰埖偄堈偄偲偄偆帠傕偁偭偰丄帺慜偺僗僋儕僾僩尵岅偺惓婯昞尰偺僶僢僋僄儞僪偲偟偰慻傒崬傫偱傒偨偑丄POSIX API偵斾傋弌棃傞帠偑憹偊偨偺偱惓婯昞尰廃傝偺僀儞僞乕僼僃僀僗偼嵞峫偑昁梫偵側傝偦偆.
傑偨惓婯昞尰僄儞僕儞杮懱偵偮偄偰偼丄撈帺奼挘偵側偭偰偟傑偆傕偺偺嵞婣儅僢僠偺堊偺婡擻傗惓婯昞尰撪偺幃丒曄悢懱宯偺僒億乕僩摍偼峫偊偰傒偰傕柺敀偄偐傕偟傟側偄 (椺偊偽屻曽嶲徠偵懳偡傞墘嶼丄a偑n屄懕偄偨屻b偑n屄懕偔傕偺偵儅僢僠偝偣傞偲偐. 傑偨曄悢宯偼lex偺忬懺慗堏傒偨偄偵巊偊傞丄傑乕壗偱傕惓婯昞尰偱傗傠偆偲偡傞偺傕娫堘偄偩偑) 偲丄傑乕偙傫側嬶崌偱僌僟僌僟偲崱擭傕傗偭偰峴偔帠偵側傞偲巚偆丄傒偨偄側偦傫側僇儞僕 (帺暘帺恎偺婍梡昻朢揑側晹暘偼傕偆彮偟夵傔偨偄強偱偼偁傞偑...:-<).
嫵壢彂偺掕斣偱偁傞偵傕娭傢傜偢梋傝嶌偭偰偄傞恖傪尒偐偗側偄惓婯昞尰偱偡偑丄偁傞掱搙偺僷僼僅乕儅儞僗偱椙偗傟偽丄婯柾揑偵傕堄奜偲扤偱傕嶌傟傞傕偺側傫偱丄堦偮嶌偭偰傒傞偺傕偦傫側偵埆偔側偄偱偡傛傒偨偄側偦傫側榖;-)
梋傝嫽枴偺偁傞暘栰偱傕柍偄偺偱偙偺掱搙偱廂傔傞偮傕傝偩偭偨偺偩偑丄寢嬊弌愭偐傜婣偭偰偒偰偐傜曗島偲徧偟偰怓乆挷傋偰偄傞偺偼壗偲傕壗偲傕丄懠偵傗傞傋偒帠偑偁傞偺偱懕偔偐懕偐側偄偐偼尰忬枹掕.
---------------
仸1) 嵟怴偺C++巇條偱偼昗弨儔僀僽儔儕偲偟偰惓婯昞尰偑僒億乕僩偝傟偰偍傝丄VS2010埲崀偱偼巊偊傞傜偟偄偺偩偑丄VC8埲崀偺儔儞僞僀儉偼傗傗僆乕僶乕僿僢僪偑戝偒偔側偭偰偄偨傝丄Win2k偱摦偔僶僀僫儕傪揻偗側偔側偭偰偄偨傝偱屄恖揑偵偼巊偄傛偆偑柍偄偺傕壗偲傕壗偲傕丄幚嵺偼unicode偱側偄偲擔杮岅偑埖偊側偐偭偨傝偲寛偟偰梡搑偑柍偄儚働偱傕側偄丄偦傟掱愊嬌揑偵堄枴偑偁傞偲傕尵偄擄偄偑(嬯徫)
傑偨奜晹儔僀僽儔儕傪巊偭偨応崌丄奜晹埶懚娭學偑1偮憹偊傞偛偲偵僜僼僩偺儕儕乕僗, 儊儞僥僫儞僗偵偍偗傞僐儞僩儘乕儖偺帺桼搙偑 1偮幐傢傟傞帠偵側傞偺偱 (偙傟偼帺慜偱偁偭偰傕椺偊偽戝婇嬈偱傛偔偁傞懠偺帺幮惢昳傪巊偆応崌偼捈愙廋惓壜擻側忬嫷偵柍偗傟偽摨偠帠丄惂栺傗僶僌偑弌偨応崌偵偦傟偑惂屼壓偵偁傞偐偳偆偐偲偄偆榖偱丄儔僀僽儔儕傗儈僪儖僂僃傾偵崌傢偣偰巇條傪寛掕偡傞偺偼(杮棃偼)杮枛揮搢恟偩偟偄) 偦傟偑丄奐敪偵偍偗傞幵椫偺嵺敪柧偺潏潐傕丄NIH徢岓孮傕庡挘偺椉嬌偱偁傝丄壗傟偺庡挘傕屄恖揑偵偼媈栤帇偟偰偄傞偑 (杮棃偺堄枴偱偼尋媶敤偺梡岅偱偁傞偺偱丄偦傟傪棟夝偟側偄傑傑巊偆帠傪梚岇偟偰偄傞傕偺偱偼柍偄帠傕娷傔偰丄偹:-P) 壗傟偵偣傛慖戰巿偺壜擻惈偑偁傞帠偼忢偵椙偄帠偱偼偁傞;-)
仸2) 堦墳NFA峔憿偐傜棃傞僨乕僞偺楢寢偵偼側偭偰偄傞偑丄暥帤扨埵偺慗堏偱偼柍偔丄徠崌婡偺楢寢偲偟偰僌儔僼峔憿傪峔抸偡傞宍偵側偭偰偄傞 (杮棃偺NFA偲偼愡揰偲巬偑媡偵側偭偰偄傞) 暥帤扨埵偺慗堏偼杮棃偺堄枴偱偺惓婯昞尰偺婡擻偐傜丄堦斒揑側乽惓婯昞尰乿偲屇偽傟傞婡擻傑偱奼挘偟偨帪偵埖偄擄偝偑尰傟傞婥偑偟偨帠偲丄峔暥夝愅偲僌儔僼峔憿嶌惉傪 1pass偱峴偆 (僐乕僪僒僀僘嶍尭偺堊丄嵟揔壔傪峫偊傞応崌偼峔暥栘偲僌儔僼峔憿偺惗惉偼暘偗偨曽偑椙偄) 偺偵搒崌偑椙偐偭偨堊偩偑丄婡擻揑側廮擃偝偼摼堈偄傕偺偺丄嵟揔壔偺壜擻惈傪峫偊偨応崌偵崱夞偺幚憰曽幃偑懨摉偱偁偭偨偐偼晄柧.
屻偱挷傋偨強偱偼悽娫揑偵偼VM(壖憐儅僔儞)偱偺幚憰傪庢傞働乕僗偑懡偄傜偟偄丄幚嵺僌儔僼傪扝傞曽幃偱偼儊儌儕偺嬊強惈偑幐傢傟傞偺偱丄僉儍僢僔儏偺塭嬁傪婜懸偱偒側偄帠偼帠幚偱偼偁傞:-<
仸3) (崱夞偺幚憰偵尷傜偢) 懎偵Traditional NFA (旕寛掕惈桳尷僆乕僩儅僩儞) 偲屇偽傟傞僶僢僋僩儔僢僋宆偺惓婯昞尰幚憰 (斈梡偺傕偺偼杦偳偙偺僞僀僾) (仸4)偺栤戣偲偟偰丄扨側傞嬻敀偺撉傒旘偽偟偱偡傜丄1暥帤偛偲偵僶僢僋僩儔僢僋僗僥乕僩傪僗僞僢僋偵愊傓昁梫偑弌偰偔傞 (扨側傞撉傒旘偽偟偑惉棫偟側偄偺偼/a+ab/偺傛偆側惓婯昞尰傪儅僢僠偝偣傞昁梫偑偁傞堊) 椺偊偽10000暥帤偺嬻敀偑偁傟偽儅僢僠偺惉斲偵娭傢傜偢 (儖乕僾摍偺懠偺僗僥乕僩傕娷傔傞偲) 嵟掅10000梫慺埲忋偺儊儌儕彂偒崬傒丄埥偄偼僗僥乕僩曐帩偺嵞婣張棟(彮側偔偲傕Java偺惓婯昞尰幚憰偺慖戰張棟偵偼偙偺庤偺栤戣偑偁傞) 偑敪惗偡傞帠偵側傝丄儅僢僠幐攕偺僆乕僶乕僿僢僪偼傛偔榑偠傜傟傞榖偩偑丄惉岟帪偱偁偭偰傕愱梡偵僷乕僒傪彂偔偺偵斾傋梱偐偵戝偒側僆乕僶乕僿僢僪偑敪惗偡傞.
婔偮偐偺僷僞乕儞偱僷乕僒傪彂偄偰斾妑偟偨強偱偼丄戝懱10攞掱搙偼堘偆報徾偱丄晄堦抳忦審偵偮偄偰傕憗婜偵婞媝弌棃傞壜擻惈偑崅偄帠傪峫偊傞偲丄壜擻側帪偼壗帪偱傕僷乕僒傪彂偔曽偑椙偄偲傕尵偊傞. 幚嵺偵偼扨側傞悢抣偺僷乕僗堦偮庢偭偰傕壜擻側僷僞乕儞傪楍嫇偡傞偲偁傞掱搙偺暘検偵側傞堊丄偪傚偭偲偟偨張棟偵巊偆偺偵偼庤娫偑偐偐傝夁偓傞偟丄傑偨暥帤扨埵偱偺張棟偵僆乕僶乕僿僢僪偑偁傝夁偓傞僀儞僞僾儕僞摍偱偼丄偦傕偦傕偑偳乕偵傕側傜側偄榖偱傕偁傞偺偩偑...:-<
傑偨暥帤楍偺僗僉儍儞張棟帺懱偼晄堦抳偺扵嶕傪娷傔傞偲O(n^2)偱偁傞偺偱尠嵼壔偟擄偄傕偺偺丄斀暅偼偦偺庴椞夞悢n偵偮偄偰*O(n)偺慖戰巿傪惗惉偟丄晄堦抳忦審偱斀暅偑僱僗僩偡傞偲埫栙揑偵O(n^3),O(n^4)...偲僐僗僩偑挼偹忋偑傞儕僗僋傪忢偵敽偆 (偙傟偵偮偄偰偼幚憰曽幃傪曄偊傞帠偱夞旔壜擻側曽朄偑偁傞偑)
偦傫側偙傫側偱丄偳乕偵傕巊偆慜偵偍暊偄偭傁偄偵側偭偰偟傑偭偨婥暘:-<
仸4) 偙偺榖偼DFA (寛掕惈桳尷僆乕僩儅僩儞) 偱偺惓婯昞尰幚憰偵偼摉偰偼傑傜側偄丄堦曽偱DFA幚憰偼僌儖乕僾拪弌傗嵟彫堦抳摍丄桳梡側婡擻偺堦晹偑幚憰晄擻 (DFA偺応崌惓婯昞尰偺暲傃偺傑傑偺徠崌偱偼柍偔丄惓婯昞尰偺庴棟偡傞暥帤擖椡偱慗堏壜擻側廤崌傪傑偲傔偰偟傑偆宍偱濨枂偝傪夝徚偡傞斀柺丄偳偺宱楬傪扝偭偨偐偺忣曬偼幐傢傟偰偟傑偆堊) 偱偁偭偨傝偲丄偁傞掱搙偺岺晇傪峫偊側偄偲丄帺桼搙偺偁傞傕偺傪幚憰偡傞偺偼擄偟偦偆偱偼偁傞. (嵟揔壔夁掱偲偟偰峫偊傞偲晹暘揑偵DFA偵曄姺偡傞幚憰傕偁傞偑丄慡懱偲偟偰DFA偺峫偊曽偱杦偳偺婡擻傪幚憰弌棃傞曽朄偑偁傞偺偐偼晄柧)
傑偨丄偙偙偱偺NFA,DFA偲偄偆尵梩偼惓婯昞尰偺幚憰偺嬫暘偲偟偰丄偦傟掱愱栧揑偱偼柍偄奅孏偱傛偔巊傢傟傞岅渂偱巊梡偟偰偄傞堊丄杮棃偺寁嶼婡妛忋偱尵偆NFA,DFA偺堄枴偲偼傗傗僘儗偑偁傞. 杮棃偼寛掕惈偲偄偆尵梩偼峔暥偺慗堏峔憿偲偟偰偺昞尰宍幃偺傒傪巜偟丄幚嵺偼NFA偺昡壙偵偮偄偰傕僶僢僋僩儔僢僋偑昁恵偲偄偆儚働偱偼柍偔丄庢傝摼傞忬懺廤崌傪慡偰娗棟偟側偑傜擖椡扝傞 (幚幙揑偵偼DFA曄姺偺忬懺廤栺偺晹暘張棟傪昡壙帪偵峴偆偺偲摍壙) 曽朄傕偁傝丄僶僢僋僩儔僢僋傪梡偄偨扵嶕偼(杮棃偺)NFA峔憿傪夝庍偡傞嵺偺堦夝朄偵夁偓側偄. 偐側傝偺悢偺惓婯昞尰幚憰偑忋婰偺 (not 愱栧揑側堄枴偺) NFA+僶僢僋僩儔僢僋偱偁傞偺偱堦斒壔弌棃傞榖偱偼偁傞偑丄寛偟偰晛曊揑側榖戣偱偼柍偄.
側偍NFA偺忬懺傪曐帩偟側偑傜堦抳偝偣傞曽朄偼(僐儞僷僀儔摍偺榖偱偼偙偪傜偑尵媦偝傟傞傕偺偺)丄僌儖乕僾拪弌摍偺惓婯昞尰傑偱奼挘偡傞曽朄偵偮偄偰偼梋傝抦傜傟偰偄側偐偭偨偑丄嬤擭Google偺Re2偺幚憰偵敽偭偰尒捈偝傟偮偮丄傑偨斾妑揑峀偔抦傜傟傞傛偆偵側偭偰偒偨柾條. 偙偺曽幃偼僌儔僼扵嶕偵偍偗傞暆桪愭扵嶕偲摨媊偱偁傝丄儖乕僾偺僱僗僩偵傛傞僗僉儍儞埵抲偺廳暋傪婞媝弌棃丄椙偔抦傜傟傞乽昦傫偩乿惓婯昞尰僷僞乕儞偵傛傞戝暆側懍搙掅壓偺塭嬁傪庴偗側偄(敜丄奺暘婒偼擖椡暥帤埵抲偱摨婜揑偵張棟偝傟丄偦偺弖娫偺忬懺悢偼昁偢惓婯昞尰慡懱偺忬懺悢埲壓偵側傞偺偱丄徠崌夞悢偼偙傟傜偺愊偲側傞偑丄幚憰偟偨儚働偱偼柍偄偺偱丄尒棊偲偟偑偁傞偐偳偆偐偼晄柧).
傑偨DFA偵偮偄偰偼惂栺偑戝偒偄傕偺偺丄惓婯昞尰僷僞乕儞偺暋嶨偝偼嬻娫僐僗僩偵偺傒揮壟偝傟丄徠崌僐僗僩偵塭嬁偟側偄. 峏偵惓婯昞尰僷僞乕儞偵偮偄偰偼暋悢偺昞尰傪寢崌壜擻偱偁傝lex摍偺暋悢婯懃偱偺token愗傝弌偟張棟偱偼1搙偺僗僉儍儞偱暋悢偺儖乕儖傪敾暿壜擻偵側傞丄偦偆偄偆堄枴偱偼堦斒揑側惓婯昞尰儔僀僽儔儕偺僀儞僞乕僼僃僀僗偑忢偵偙傟傜偺嬅偭偨峔暥夝愅偵懳偟戙梡壜擻偲偄偆榖偱傕柍偄.
---------------
梋択偩偑丄奐敪夁掱偱弌偨僶僌傪婛懚偺幚憰偲斾妑偟偰妋擣偟偰偄偨傜Java偺惓婯昞尰偺僶僌傪1偮尒偮偗偨偭傐偄丄撪梕偼
(?=(foo))...bar|\1[0-9]+
偑
"foo99"
偵儅僢僠偟偰偟傑偆偲偄偆傕偺偱丄愭撉傒偑match偵惉岟偟偨屻丄屻懕偑match偵幐攕偟偨応崌偵偦偺愭撉傒晹偺僗僥乕僩偑惉岟忬懺偺傑傑幪偰傜傟偰偄側偄偲偄偆榖(JDK
1.6.0_20偵偰妋擣)
摉慠偙傫側惓婯昞尰傪彂偔偺偼娫堘偄偩偑丄忋婰偼撈棫晹 (?>乣) 傗嫮梸側悢検巕 *+ 摍偱傕敪惗偟偰偍傝丄偙傟傜偼幚憰偲偟偰徠崌晹偐傜撈棫偟偨惓婯昞尰傪嵞婣揑偵揔梡偡傞宍偵側傝摼傞売強偱丄杮幙揑側栤戣偲偟偰偼丄嵞婣張棟偑惉岟偟偨屻偱屻懕偑幐攕偟偨応崌偵丄嵞婣晹偺儖乕僾忬懺摍偺撪晹僗僥乕僩偑夞暅偝傟側偄傑傑嵞搙match偑帋峴偝傟傞宍偵側偭偰偟傑偆傗傕丄偲偄偆傛偆側堦枙偺晄埨傪姶偠偰傒偨傝.
幚憰偺撪梕師戞側偺偱栤戣偵側傜側偄壜擻惈傕偁傞偟丄Oracle強桳偵側偭偰偐傜偼惓捈婥帩偪埆偄(徫)帠傕偁偭偰嵟怴偺傕偺偼擖傟偰偄側偄偺偱丄婛偵bugfix偝傟偰偄傞傗傕偟傟側偄偑丄傑丄堦墳儊儌偑偰傜偲偄偆強 (偲偄偆掱Java偼巊傢側偄偗偳丄Web壆偠傖柍偄偺偱帺暘揑偵偼梡搑柍偄偟(徫)
側偍偙傟埲奜偵Java偺惓婯昞尰僄儞僕儞偱偼 | 偱楢寢偝傟傞梫慺偺斀暅偑懕偔偲僗僞僢僋僆乕僶乕僼儘乕傪婲偙偡偲偄偆傕偺傕偁傞丄婎杮揑側傾儖僑儕僘儉偲偟偰偼斀暅偲慖戰偼摨條偵徠崌偺暘婒傪惗偠傞偺偩偑丄扨弮側斀暅偱偼敪惗偟側偄帠偐傜丄撪晹嵟揔壔偺暘偐傝擄偄惂栺偲偟偰懚嵼偟偰偄傞柾條. 杮棃慖戰晹偼傾儖僑儕僘儉揑偵偼嵞婣傪梡偄側偔偰傕婰弎壜擻側偺偱丄扨弮偵幚憰忋偺惂栺偲偄偆帠偵側傞.
僼傿儖僞偼2屄栚幚憰姰椆丄偁偲1偮婥偵側傞僼傿儖僞偑偁傞偑丄偦偺慜偵崱夞偺僼傿儖僞偱幚憰偟偨傾儖僑儕僘儉偺暃嶻暔偲偟偰峫偊摼傞傕偺傪専摙.

偙傫側嬶崌偵巊偊傞傕偺偱丄慖戰斖埻偵傛傝擟堄偺宍忬偵懳墳壜擻偩偑丄傑偲傕偵昞尰偺壜擻惈傪峫偊傞偲3D偺幙姶愝掕偲傎傏摨條傑偱昁梫偵側傝偦偆偱彮乆摢偑捝偄丄傑偩帋偟偰偄側偄偑撪晹忣曬偺惛搙揑偵偼娐嫬儅僢僾偱偺斀幩丒孅愜偺昞尰傕壜擻偩偲巚傢傟傞. 扐偟摟柧懱偺応崌偵傾儖僼傽傪曄摦偟偰傕僇儔乕僈儔僗偺傛偆側昞尰偼儗僀儎乕偺崌惉儌乕僪揑偵扨堦儗僀儎乕偱偼擄偟偄偲巚傢傟傞偺偱丄強慒偼尷奅偼偁傞偩傠偆.
傑偨傾儖僑儕僘儉揑偵庛揰傕偁傞偺偱丄暿偺僷僞乕儞偵懳墳偡傞堊偺傾儖僑儕僘儉傕専摙拞偩偑丄偙偪傜偼僺僋僙儖尷奅偱偺僄儔乕娷傒偺墘嶼偱偁傞偺偱丄暯嬒壔摍傪梡偄偰傕廫暘偲屇傋傞昳幙偵摓払偝偣傜傟傞偐丄傑偨懍搙揑偵傕擄偑偁偭偨傝偲怓乆擸傑偟偔丄嵟廔揑偵偳偺傛偆側宍偱摑崌偝偣傞偐偺僀儊乕僕傕傑偩屌傑偭偰偄側偄.
傑乕丄偦傫側嬶崌偱榚摴偵偦傟偨宍偱怓乆専摙拞丄埲慜KOJI偝傫偲榖偟偨摟柧懱傗嬥懏傪昞尰偡傞榖偼丄強慒尦僨乕僞偼2D偲偄偆帠偱偼懡暘偙偺曈傝偑棊偲偟強偱偼側偄偐偲巚偆偑偳傫側傕偺偩傠偆?
傑乕偟偐偟忋偺夋憸偼壗偲傕擇棳偭傐偄偄偐偵傕側僨僐儗乕僔儑儞僗僞僀儖傗偹丄僙儞僗柍偄傢(嬯徫)
# 崱寧枛偵婔偮偐梡帠偑偁傝丄偦偺婜娫偼廫暘偵僾儘僌儔儉傪彂偗傞偲偼尵偄擄偄忬嫷偵側傞偺偱丄偦傟傑偱偵偳偺掱搙弌棃傞偐偑彑晧偱偼偁傞丄娭楢偟偨榑暥傕1杮撉傑側偒傖側傜側偄偭傐偄偟丄傗偼傝撍偭崬傫偩榖偲偄偆偺偼梋傝擔杮岅偺儕僜乕僗偑柍偄偺偑壗偲傕尩偟偄傗偹:-<
---------------
彮偟慜偺榖偩偑丄帺慜偺懡攞挿墘嶼儔僀僽儔儕偱悢妛娭悢宯偺幚憰傪傗偭偰偄偨偑丄梋傝偵廂懇寁嶼偑抶偐偭偨偺偱埲慜偐傜婥偵側偭偰偄偨Karatsuba朄傪幚憰偟偰傒偨丄傾儖僑儕僘儉偩偗尒偨強偱偼峔憿揑偵儖乕僾偵曄姺偡傞偺偑崲擄偦偆側壜曄僒僀僘偺拞娫僶僢僼傽傪巊梡偡傞宍偱偺嵞婣揑側張棟偑昁梫側偺偱丄杮摉偵偙傟偱懍偔側傞偺偐偲夰媈揑偱偼偁偭偨偑丄幚憰偟偰傒偨強偦傟側傝偵岠壥偑偁傞柾條.
側偍幚憰偼嵞婣揑偵Karatusba傪揔梡偟忔悢偺1曽偺桳岠寘偑岠棪揑偵張棟偱偒傞掱搙偵側偭偨応崌 or 慡懱偺寘悢偺捈愙寁嶼偺僐僗僩偑嵞婣偺僆乕僶乕僿僢僪傛傝傕寉偔側傞帪揰偱捈愙寁嶼偵愗傝懼偊傞偲偄偆斾妑揑僔儞僾儖側傕偺偱丄寁嶼僐僗僩偼堄幆偟偨偑丄嵞婣偵偮偄偰偼慺捈偵嵞婣屇傃弌偟偲偟偰幚憰.
扐偟幚憰偺栤戣傕偁傞偐傕偟傟側偄偑丄RSA偵巊梡偡傞傛偆側1024乣4096bit (10恑偱偼偣偄偤偄300乣1200寘) 掱搙偱偼偣偄偤偄1.5攞掱搙懍偔側傞掱搙偱丄柧妋側壎宐偑摼傜傟傞偺偼悢愮乣悢枩寘掱搙埲忋偲偄偆報徾偱偼偁偭偨.
傑乕偩偐傜偳乕偟偨偲偄偆掱搙偺榖偱偼偁傞偑丄夛幮帪戙 (傕偆10擭傕慜偵側傞) 偵RSA傪専徹偟偨嵺Karatsuba偼挷傋偼偟偨偑丄幚憰偵傑偱偼帄傜側偐偭偨偺偱丄偦偺10擭慜偺曗島偲偄偭偨強(徫)
幚嵺偵偼椺偊悢枩寘偁偭偰傕彍嶼傪巊偊偽寢壥偼梕堈偵柍棟悢偵棊偪丄寁嶼偼忢偵岆嵎傪憹暆偟摼傞偟丄桳尷惛搙偱惍悢柍尷偺彫悢屌掕偲偄偆峫偊曽 (Java偺BigDecimal偲偐) 偼堦斒揑側寁嶼偱偼埆偔側偄偑丄媄弍寁嶼宯偱偁傟偽 (傛偔偁傞寁嶼偺曄宍偱) 媡悢傪庢偭偨帪揰偱梕堈偵攋抅偡傞. 巐懃墘嶼宯偵桳棟悢傪梡偄傞帠傪峫偊傞偲捠忢偺巐懃墘嶼偱偼岆嵎偼娷傑側偄偑悢妛娭悢傗掕悢傪巊偆偲忬嫷偼戝偟偰曄傢傜側偄 (偐偮愽嵼揑側岆嵎偼捠忢偺懡攞挿傛傝傕弌曽偑婏柇側怳傞晳偄偵側傝摼傞丄傑偨惓婯壔偱Euclid偺屳彍朄傪懡梡偡傞帠偐傜婎杮梫慺偼10恑婎悢偱偼柍偔丄2恑婎悢偱側偗傟偽尩偟偄偲巚傢傟丄2恑壔岆嵎傕愽嵼揑偵曪桳偡傞帠偵側傞) 偦傫側嬶崌偱傑偩帺暘偺拞偱棊偲偟強偑掕傑傜側偐偭偨傝偲丄懡攞挿墘嶼宯偼屻2夞埵偼嶌傝捈偡昁梫偑偁傝偦偆側梊姶(嬯徫)
# 傑乕偙偺帪偺惉壥偼堦捠傝偺悢妛娭悢偺幚憰偑懡攞挿堟偱偁傞掱搙幚梡揑側懍搙偱廂懇偡傞傛偆側曄宍傪摼傜傟偨 (扐偟1枩寘偲偐偵側傞偲悢昩order偱偼偁傞) 帠(仸1)偱偁傞偺偱 (晜摦彫悢堟偱偼栤戣柍偄懍搙偱廂懇偡傞傕偺偱傕丄偦偺傑傑懡攞挿偵揔梡偡傞偲廂懇偑嬌傔偰抶偔側傞傕偺偑偁傞) 忋偺榖偼偦偺堦娐掱搙丄偁偔傑偱婥偵側偭偰偄偨撪梕偺徚壔偲偄偆榖偱偟偐柍偄偺偩偑丄堦墳偺儊儌偑偰傜;-)
# 側偍偙偺帪偺娭悢寁嶼偼堦晹newton朄偩偑丄杦偳偼(峀偄堄枴偱偺)Tayer揥奐偲廂懇堟傊偺幃曄宍傪巊梡丄応崌偵傛偭偰偼楢暘悢揥奐偺曽偑廂懇偑憗偄傕偺傕偁傞偑丄惛搙偵墳偠偨慟壔幃傪嶌惉偡傞偺偑彮乆柺搢偱偁傞偺偱崱夞偼曐棷丄幚嵺楢暘悢揥奐偱偺惛搙専徹偱偼媺悢揥奐斉傕昁梫偵側傞偺偱庢傝姼偊偢偼偙傟偱椙偐傠偆偲偄偆強丄媺悢揥奐斉偼惛搙傪曄偊偨応崌偵傕廋惓偼傎傏晄梫偱偁傞偺偱丄僔儞僾儖側儔僀僽儔儕偲偟偰偼埖偄堈偄帠傕偦傟側傝偵棙揰偱偼偁傞偲偄偆僇儞僕.
仸1) 偙傟傕尦乆偼峴楍偵懳偡傞挻墇娭悢偺幚憰偺慜抜偲偟偰僗僇儔偱偺張棟傪傕偆堦搙尒捈偟偰偍偙偆偲偄偆榖偱丄峴楍偵懳偡傞挻墇娭悢 (椺丗 exp(A), A偼擟堄偺惓曽峴楍) 偼峴楍偺惍悢傋偒寁嶼偑掕媊偝傟傞帠偐傜丄嬌尷揑偵巜悢丒懳悢娭悢偑峫偊傜傟丄偝傜偵偦偺曄宍偐傜擟堄悢抣丒峴楍偱偺傋偒忔偑掕媊偝傟丄傑偨巜悢娭悢偵懳偡傞僆僀儔乕偺曄宍偵傛傝嶰妏娭悢傕峫偊傞帠偑壜擻偲側傞.
幚嵺丄峴楍偺挻墇娭悢偼媺悢揥奐偲峴楍偺屌桳抣丒屌桳儀僋僩儖峴楍偵傛傞懳妏壔A==V.兩.inv(V)傪峫偊傞偲傋偒墘嶼偲僗僇儔學悢偱偺慄宍寢崌傪慻傒崌傢偣傞尷傝 (偮傑傝媺悢揥奐偺墘嶼偑壜擻) 峴楍偺屌桳抣偵懳偡傞墘嶼偲懆偊傞帠偑壜擻偱丄偙偺摿惈偼幚嵺偵峴楍傪梡偄偨旝暘曽掱幃偺夝偲偟偰梡偄傜傟傞帠偵側傞. 扐偟忋婰偼峴楍A偑懳妏壔壜擻側応崌偵偺傒屌桳抣暘夝偱捈愙寁嶼偑壜擻偱偁傞偑丄幚嵺偵偼懳妏壔偑晄壜擻側応崌偵傕掕媊偝傟傞堊丄廫暘偵廂懇偝偣傞帠偑壜擻偱偁傟偽 (幚嵺偼偙偙偑栤戣偱丄僗僇儔偺応崌偵偼扨堦偺抣偺傒廂懇堟偵堏偣偽椙偄偑丄峴楍偺応崌慡偰偺屌桳抣偵偮偄偰偦傟偑惉棫偟側偗傟偽側傜側偄:-<) 曄宍丒媺悢揥奐側偳偐傜媮傔傞曽偑 (岆嵎偼偲傕偐偔偲偟偰) 斈梡惈偑偁傞偲偄偆榖.
傑乕壗偐偦傫側嬶崌偵彂偔偲傗傗偙偟偦偆偩偑丄偙偺惈幙傪埲偭偰峴楍偵傛傞曄姺偼n師尦奼挘偝傟丄屄暿偺幉傪帩偭偨妡偗嶼偲偟偰斾妑揑捈姶揑偵懆偊傞帠偑壜擻側婥偑偟傑偣傫偐?傒偨偄側偦傫側僇儞僕偱;-)
僋儔僂僪偑尪柵婜偵擖偭偨偲偄偆暘愅傪挷嵏夛幮偑弌偟偨偲偄偆僯儏乕僗傪尒偰偄偰丄傆偲巚偄棫偭偰専嶕偟偰傒偨傜...壗偐崜偄帠偵側偭偰偄傞.
偦傟埲奜偵傕乽僋儔僂僪偭偰壗乿偱専嶕偟偰傒傞偲嶳掱弌偰偔傞偑丄壗帪偺娫偵偐僋儔僂僪偑僀儞僞乕僱僢僩偺傛偆側敊慠偲偟偨傕偺傪夘偟偰丄偲偄偆堄枴偵側偭偰偄傞傜偟偄. 僶僘儚乕僪偲偟偰巊傢傟偩偟偨崰偐傜丄戝懱偼偦傫側強偵棊偪拝偔偩傠偆偲巚偭偰偄偨偟丄傑偨偦偆側偭偰傞側乕偲偼姶偠偰偄偨偺偩偗偳丄夵傔偰偪傖傫偲堄幆偟偰尒傞偲丄壗偲尵偆偐丄傑乕曫傟傞傪捠傝墇偟偰嵟憗尵梩傕弌側偄僇儞僕.
岆夝傪嫲傟偢偵尵偆偲丄彮側偔偲傕僋儔僂僪偑榖戣偵側傝巒傔偨帪偺掕媊偱偼暘嶶僐儞僺儏乕僥傿儞僌偲棈傔偰岅傜傟偰偄偨偲巚偆偺偩偑. 戝傑偐側昞尰偩偑丄憤懱偲偟偰1偮偺僐儞僺儏乕僞 (昞尰忋偺堊傗傗娙棯壔偟偨昞尰) 偲偟偰怳晳偆僐儞僺儏乕僞偺廤崌懱偱偁傝丄壖憐壔媄弍摍傪墳梡偡傞帠偱懡彮偺愗傝懼偊偩偗偱1偮偺僾儘僌儔儉偵懳偡傞儕僜乕僗攝暘傪嬌傔偰廮擃偵 (廬棃偺壖憐僒乕僶摍偲堎側傝壖憐儅僔儞偺嵞婲摦摍偺柧帵揑側愗傝懼偊傕彮側偔偲傕昞柺忋偼峴傢側偄偱) 峏偵偼幚峴帪偺僾儘僼傽僀儖摍傪尦偵忬嫷偵傛偭偰偼儕傾儖僞僀儉偱偝偊傕廮擃偵僾儘僌儔儉偵懳偡傞儕僜乕僗攝暘傪曄偊傜傟丄僔僗僥儉傪憹愝偡傞尷傝柍尷 (昞尰忋偺傕偺偱幚嵺偼嬌傔偰戝偒偄偲摨媊) 偺幚峴丒婰壇儕僜乕僗傪巊梡偱偒傞傛偆側戙暔傪巜偟偰偄偨敜.
扐偟幚嵺偵偼婛懚偺僔僗僥儉忋偺僾儘僌儔儉偺幚峴宍幃丒幚峴宍懺偱偼偦偆偄偭偨帺摦揑側暘嶶壔傪僒億乕僩弌棃側偄堊丄愱梡偺僔僗僥儉忋偺惂栺偺壓偱1屄偺僐儞僺儏乕僞偲偟偰怳晳傢偣傞堊偺儗僀儎傪掕媊偡傞昁梫偑偁傝丄偙偺拪徾壔奒憌偑僾儘僌儔儉幚峴僾儔僢僩僼僅乕儉偺偳偺奒憌偐傜拪徾壔偡傞偐偵墳偠偰PaaS, SaaS, IaaS側偳偺暘椶偑惗偠傞偲尵偆榖偩偭偨偲婰壇偟偰偄傞偺偩偑丄偮傑傝cloud偱偁傞偲摨帪偵crowd偱偁傞僔僗僥儉偱側偗傟偽僋儔僂僪偲偼晛捠尵傢側偄傫偠傖側偐傠乕偐?
怓乆僋儔僂僪偲柫懪偭偨僒乕價僗傪専嶕偡傞偲嵟嬤偼僱僢僩傪夘偟偰屻偼偣傔偰壖憐壔 (壖憐壔僒乕僶偺僒乕價僗帺懱偼僋儔僂僪偺慜偐傜巊傢傟偰偄傞偟) 媄弍掱搙偱傕僋儔僂僪偲柤忔偭偰椙偄傜偟偄丄偄傗擩傠僱僢僩傪夘偡偩偗偱傕僋儔僂僪偱偁傞傜偟偄(佹僱僢僩==僋儔僂僪偱偁傞堊). 屻偼偣偄偤偄傛傝嵶偐偄扨埵偺壽嬥懱宯偱廮擃惈傪鎼偆 (偙傟傕忋偺榖偺廮擃惈偲偼暿偺榖) 偲偐偭偰丄偦傫側偺愄偐傜偁偭偨榖偩偟. (傑乕偙傟傕峴偒夁偓傞偲僟儉抂偲偐X抂枛偲偐丄埥偄偼儊僀儞僼儗乕儉偵僕儑僽傪搳偘傞偺傪巜偟偰僋儔僂僪偼愄偐傜偁偭偨側傫偰儚働偺暘偐傜側偄帠傕尵偊偰偟傑偆偺偐傕偟傟側偄偑(徫)).
壗偐wikipedia偺婰弎偡傜僇僆僗偩偟丄僐儞僺儏乕僞嬈奅偭偰傗偭傁傝媬偄擄偄偺偐偹偉(仸1)
...埥偄偼偍偐偟偄偺偼帺暘偺曽偩偲偄偆壜擻惈偺婎杮擇戰偱(嬯徫)
仸1) 傑丄僐儞僺儏乕僞嬈奅偵尷傜側偄偗偳丄偐側傝愄偩偗偳僼傽僕傿偲偄偆梡岅傪懡梡偟偨壠揹嬈奅偲偐丄傾儗傕n抜奒僥乕僽儖堷偒傪僼傽僕傿棟榑偱尵偆強偺僼傽僕傿惂屼偲偼尵傢偹乕傒偨偄側僔儘儌僲偩偭偨偟. 屌桳柤帉偱壔妛偱尵偆偺偲偼慡偔暿暔偺儅僀僫僗僀僆儞偲偐丄僀僆儞壔偟偨婥懱偭偰丄偦偺傑傑壔妛梡岅偲徠傜偟崌傢偣傞偲傑偝偐僾儔僘儅 (揹棧婥懱丄揹壸偼媡偩偗偳) 偐傛丄傒偨偄側 (埨掕偟偰暘棧偟偨忬懺偺僾儔僘儅偑曻弌偝傟傞嬻婥惔忩婡偲偐偑桳傟偽偦傟偼偦傟偱柺敀偄偑(徫) 側偍堦墳儊乕僇乕偼懷揹婥懱傪巜偟偰尵偭偰偄傞傜偟偄丄岠擻偵偮偄偰偼椙偔偁傞帡旕壢妛偺堟傪弌偰偄側偄丄恖娫傗偭傁傝惤幚偵惗偒偨偄傕偺偩傛偹丄側傫偰尵偭偰傒傞:-P).
愭擔彂偄偨PNG偺儔僀僽儔儕壔偼傕偆巄偔曐棷丄儊儌儕偺柍懯偑婥偵側偭偰偄偨偑丄埑弅儘僕僢僋偑暿側偣偄偐丄埑弅偺曽偼偄偗傞偑揥奐晹傪姰慡偵僗僩儕乕儉壔偡傞偺偑彮乆擄偟偦偆偩偲偄偆寢榑偵. 僄儞僨僐偺応崌朷傑偟偔偼弴師撉傒崬傒偱儔僗僞扨埵偺僐乕儖僶僢僋偺傛偆側宍偱偁傞偺偑朷傑偟偄偺偩偑丄儔僗僞側偳偺扨埵偱埑弅僨乕僞偑暘棧偝傟偰偍傜偢丄僼傿儖僞張棟側偳傕偁偭偰揥奐晹偱偼堦帪揑偵偁傞掱搙偺揥奐夋憸傪帩偮昁梫偑偁傞偺偑偐側傝寵側僇儞僕丄摿偵僀儞僞乕儗僗傑偱峫椂偟偨嵺偵鉟楉側慻傒棫偰偑巚偄偮偐偢丄嵶偐偔傾儘働乕僔儑儞偑擖傞偲僔儞僌儖僗儗僢僪偱偼 (屇傃弌偟姰椆帪偵偼慡偰僋儕傾偝傟傞偺偱) 梋傝栤戣柍偔偲傕儅儖僠僗儗僢僪帪偺僸乕僾偺僼儔僌儊儞僩偑彮乆怱攝偱傕偁偭偨傝偲梋傝椙偄慻傒棫偰偑巚偄偮偐側偄 :-<
柍棟栴棟傗偭偰傕偐側傝儖乕僠儞傪嵶愗傟偵偟側偗傟偽側傜側偄僇儞僕偱丄埲慜忕択偱嶌偭偨C++偱偺yield傪巊偍偆偐偲傕杮婥偱峫偊偰偟傑偭偨:-< 側偍僐儖乕僠儞偑梸偟偄偲巚偭偨偺偼偙傟偑2夞栚丄1夞栚偼MIDI偺墘憈僪儔僀僶 (not 僨僶僀僗僪儔僀僶) 傪嶌偭偨嵺偺僠儍儞僱儖惂屼偩偭偨偑丄傑偀 (僎乕儉宯埲奜偱偼) 杦偳偺働乕僗偱偼昁梫柍偄 (捠忢偺曽朄偱慗堏娗棟偟偰傕偦傫側偵庤娫偱偼柍偄) 戙暔偩偑丄傗偭傁傝偁傞偲曋棙側嬊柺偼傢偢偐側偑傜偵偁傞傕偺偩側偀側傫偰巚偭偰傒偨傝.
偙偺曈傕偆彮偟帺慜偺尵岅偵慻傒崬傫偱怓乆帋偟偰尒偨偄強偩偑丄僐儖乕僠儞傪幚憰偡傞応崌娭悢撪傪僼儔僢僩側媅帡僐乕僪偵曄姺偱偒傞峔惉偵偟偰偄側偄偲幚憰偼擄偟偔丄尰忬偺峔暥奒憌傪偦偺傑傑扝偭偰偄傞幚憰偱偼懳墳偱偒側偄. 傑偀丄偙傟偼偙傟偱怓乆側暥朄偺僥僗僩幚憰偑妝偩偲偄偆儊儕僢僩偑偁傞偺偩偑(徫) 偙偺曈怓乆傕偆彮偟帺暘偺拞偱屌傑偭偨傜丄偁偲1夞掱搙偼嶌傝捈偟傪偡傞帠偵側傝偦偆側梊姶.
偙偙偺強僌儔僼傿僢僋宯偺僾儘僌儔儉偑嫽偵忔偭偰偄傞偺偱丄僼傿儖僞偺巆審傪専徹拞丄慺嵽偺堊偺慺嵽嶌傝偱偼柍偔丄晛捠偵巊偆掱搙偱偼杦偳昁梫偲巚傢傟傞僼傿儖僞偼幚憰偟偰偁傞偺偩偑丄3乣4揰掱昁梫偩偲巚偆傕偺偺丄幚憰曽朄偑巚偄偮偐偢偵曐棷偵偟偰偄偨儌僲偑桳傞.
傑偢堦揰栚偼庢傝姼偊偢忋庤偄嬶崌偵寁嶼幃偑弌偣偨偺偩偑丄寁嶼検偑僷儔儊乕僞抣偺2忔偵業崪偵斾椺偡傞偺偑寵側僇儞僕丄摿偵徣棯弌棃側偄僼傿儖僞偱梡偄傞婎杮摿惈偺婔壗寁嶼偱廳偄偺偱丄岆杺壔偟偑岠偒擄偄屄強偱偁傝擸傑偟偄強. 慡晹傗傞偐偳偆偐偼寛傔偰側偄偑丄偙傟偲屻堦揰埵偼幚憰偵憜偓晅偗偨偄強偱偼偁傞.
---------------
傾僾儕壆偺桭恖偲Microsoft偺XP崰偐傜偺柪憱偵偮偄偰偼傛偔榖偡偑丄彮乆僱僞偵偟偨偺偱.
傑偀丄帺暘偑姶偠偰偄傞婋湝偼庒姳堘偆榖偱丄寢嬊.NET曈傝偐傜MS偑偁偨偐傕師悽戙API偲偟偰寲揱偟偰偄傞僥僋僲儘僕偺杦偳偑僆儌僠儍側偺偱偼柍偄偐偲偄偆強. 偙傟傜偺婡擻偱SAI偑嶌傟傞偐丄PhotoShop傗AfterEffect偑嶌傟傞偐丄LightWave傗Max,Maya etc. 埥偄偼岺嬈梡偺CAD丄忳曕偟偰傕Office僋儔僗偺傾僾儕丄傑偨彜梡DB偺僐傾僄儞僕儞摍偑嶌傟傞偐偲偄偆強. 僟僀傾儘僌偵栄偺惗偊偨掱搙偺僜僼僩側傫偧丄嬌榑偡傟偽偁傞掱搙偄偄壛尭偵婘忋偺嬻榑偩偗偱僼儗乕儉儚乕僋傪僨僓僀儞偟偰傕偦傟側傝偵偮偠偮傑崌傢偣偼弌棃傞儚働偱丄僷僼僅乕儅儞僗側偳傪撍偒媗傔偨応崌偵傕摨條偵寢壥偑弌偣傞傕偺偱柍偗傟偽乽API乿偲偟偰偺懚嵼堄媊偼柍偄 (崅偄梫媮偵尒偊傞偐傕偟傟側偄偑丄儐乕僓乕偵偲偭偰偼忋婰偺傛偆側僜僼僩偼偛偔乽偁偨傝傑偊乿偺懚嵼偱偁傞偺偱丄偦傟偵晄廫暘偱偁傞偲偄偆偺偼廫擇暘偵乽API偲偟偰偼乿榑奜偲尵偊傞)
柍榑偦傟側傝偵偼嶌傟傞偺偩偑丄帺暘偑崱傑偱怗傟偰偒偨僜僼僩偱偼丄悽偵弌偰偄傞.NET惢偺偁傞掱搙暋嶨側傾僾儕偺戝敿偑 (尒塰偊偼偲傕偐偔) 僷僼僅乕儅儞僗摍傪娷傔偨憤崌揑偵偼丄Native偱幚憰偝傟偨傕偺偵戝偒偔楎偭偰偟傑偆(仸1).
偦傟傪尒嬌傔傞堊偵傕怓乆怴偟偄媄弍傕挷傋傞偺偩偑丄壗偲尵偆偐丄擼揤婥側庒偄僾儘僌儔儅偺憐掕偺娒偝偺傛偆側媗傔偺娒偝偲丄偦偺偦偺栤戣偵懳偡傞夞旔嶔偺慖戰巿偺寚擛丄埥偄偼嬌傔偰尷掕偝傟偨慖戰巿偟偐柍偄帠偵偦傕偦傕偺憐掕偺娒偝傪姶偠傞強偑懡乆偁傝丄惓捈恀偭摉側傾僾儕 (嵟掅慄MS Office掱搙偺暋嶨偝偺傕偺) 傕慻傫偩帠偺柍偄摢偱偭偐偪偺僼儗乕儉儚乕僋壆偺帺屓枮懌偱僨僓僀儞偝傟偰偄傞偺偱偼偲偄偆傛偆側寵側乽姶怗乿(仸2)偑偁傞:-<
婅傢偔偽帺暘偑擭傪偲偭偰摢偺屌偄寵側擭婑傝偵側偭偨偩偗偱丄瀀桱偱偁傞帠傪婩傝偨偄強. 偱傕偙偙巄偔怴婯偺僥僋僲儘僕偵偮偄偰桭恖偲榖偟偰偒偨撪梕偼寢峔摉偨偭偰偄傞偺偑壗偲傕暋嶨側婥暘 (3DTV娭學偩偗偼偪傚偭偲奜傟偨偗偳) 屻偱帺暘偺摝偘摴傪嵡偖堊丄埥偄偼屻偱媬傢傟傫偑堊(徫)偵傕丄懡暘WinRT傕懯栚偩傠偆(仸3) 偲偙偙偵彂偄偰偍偔帠偵偟傛偆(徫...偭偰椙偄偺傗傜暋嶨側婥暘:-<
仸1) 僜僼僩偺儐乕僓乕偵尒偊傞婎弨偼忢偵嫞崌惢昳偲偺憡懳昡壙偵側傞丄偮傑傝1偮偱傕Native偱幚憰偝傟偨僜僼僩偑偁傞尷傝丄斾妑偝傟傞僜僼僩偼偦傟偵楎偭偰偄偰偼側傜側偄帠偵側傝丄昗弨API傊偺梫媮偼斾妑偝傟傞懠幮惢昳偲摨悈弨偺傕偺傪奐敪壜擻偱側偗傟偽側傜側偄帠偵側傞.
仸2) 幚嵺帺暘帺恎傑偩恖偵壗偐尵偊傞偩偗偺奐敪宱尡偑偁傞偲偼尵偄擄偔丄偣偄偤偄傛偆傗偔恖暲傒 (晛捠偺恖偑尒偰僜僼僩僂僃傾偩偲擣幆偱偒傞) 掱搙偺傕偺偑嶌傟傞傛偆偵側偭偨偵夁偓側偄丄偦偺帺暘掱搙偺宱尡偱乽偡傜乿偦偆姶偠偰偟傑偆帠偑擩傠戝偒偔媈栤傪姶偠傞:-<
仸3) 棟桼偼僾儔僢僩僼僅乕儉偺僨僓僀儞偐傜奐敪帺懱傪庢傝姫偔廃曈娐嫬丒忦審傗婇嬈偵偲偭偰偺愴棯偺慖戰巿摍乆丄暥復偵偡傞偲梋傝偵懡偄偺偱徣棯偡傞偗偳 (傛偔嶨択偱榖偟偰偄傞撪梕偲摨偠) Active Desktop Strikebacks!! 偵側傞傫偠傖側偐傠乕偐丄傒偨偄側.
# 忋偼偁偔傑偱昗弨乽API乿偲偟偰偼偺榖丄傕偆堦偮埆偄梊姶偲偟偰丄堦楢偺僥僋僲儘僕傪MS偼師悽戙偺API偺傛偆偵寲揱偟偰偄傞偑丄幚偼戝偘偝側扨側傞僙乕儖僗暥嬪偱丄偦偺幚偼偣偄偤偄旕忢偵椙偔弌棃偨 (偁偺帪戙偺) VisualBasic掱搙偺戙暔側偺偱偼側偄偐偲偄偆梊姶傕...ouch.
傑乕抦傜側偐偭偨偺偑埆偄偲尵偊偽埆偄偺偩偑丄昞戣偺捠傝. .NET偺Windows Form偱ToolTip傪柍堷悢僐儞僗僩儔僋僞偱嶌傞偲柧帵揑偵Dispose偟偰傗傜傫偲儕乕僋偡傞偺偩偦乕側丄IDE偺僨僓僀僫偑揻偄偨僐乕僪偱偼Form偺儊儞僶偵Container傪埫栙揑偵嶌惉偟偰丄偦傟傪夘偟偰Dispose偺僠僃乕儞傪幚尰偟偰偄傞. 傑乕IDE巊偭偰偄傟偽婥晅偄偨榖側偺偱娫敳偗偲尵偊偽娫敳偗.
妋偐偵ToolTip側傫偐偼帺慜偱巊偭偰偄傞C++偺儔僀僽儔儕偱傕壗張偵昍晅偗偡傞偺偐丄彮乆擸傑偟偄婡擻偱偼偁傞偺偩偑丄DB傗僱僢僩儚乕僋僐僱僋僔儑儞側傫偐偺斾妑揑暘偐傝堈偄愗傝暘偗偺Dispose偲堘偭偰丄偁傞掱搙僼儗乕儉儚乕僋偲偟偰儅僱乕僕僪偱儔僢僾偝傟偰偄傞傛偆偵尒偊傞GUI僷乕僣偱敪惗偡傞偲偄偆偺偼壗偲傕壗偲傕.
偦傟埲奜偵偼ContextMenu偼儕乕僋偟側偄偗偳ContextMenuStrip偼摨偠傛偆偵屇偽側偄偲儕乕僋偡傞偲偐 (偮傑傝恊巕娭學傪屻偱偄偠傟傞傛偆偵偟偰偄傞偣偄偐丄popup宯偺幚憰偑夦偟偘) ADO.NET宯偺GUI僷乕僣偱偼僨僓僀僫傪夘偟偰傕僨僓僀僫偺揻偔僐乕僪偑Dispose偺僠僃乕儞傪堄幆偟偰側偔偰庤摦偱Dispose傪彂偄偰傗傜側偄偲儕乕僋偡傞偲偐丄嵶偐偔捛偭偰側偄偺偱愭偵彂偄偨傛偆側榖偑塭嬁偟偰偄傞偐傕偟傟側偄偑 (幚嵺扨弮側僥僗僩僾儘僌儔儉偱偼嵞尰偟側偐偭偨偺偱懠偺嶲徠偺寢壥偱偁傞壜擻惈傕偁傞) 巕Form傕昞帵偟偨屻偱Dispose偟側偄偲儕乕僋偺尨場偵側偭偰偄偨 側傫偰榖傕偁傞傜偟偄.
Dispose傪屇偽側偒傖儕僜乕僗偺夝曻偑抶傟偰丄応崌偵傛偭偰栤戣偵側傞偲偄偆偺側傜暘偐傞偗偳. 杮棃嶲徠傪奜傟偰偄傞敜偱偟偐傕奣擮揑偵偼僾乕儕儞僌摍偲傕娭學柍偄屄強偱GC偐偗偰傕巆傞偭偰偺偼偳乕側傫偩偲偄偆僇儞僕. 嫇摦偲偟偰偼媡偺榖偵偼側傞偑ActionScript(Flex)偱傕旕摨婜僀儀儞僩傪曄悢偱曐帩偟偰側偄偲徚偊傞側傫偰榖傕偁偭偰戝偄偵堔偊偨儚働偩偗偳 (僼儗乕儉儚乕僋懁偱僉儏乕偵嶲徠帩偭偰偍偔傛偆偵偱傕偟偰偍偗傛偲巚偭偨傝) 偦傕偦傕偑GC宯尵岅偺儊儕僢僩偭偰壗傛丄傒偨偄側偙偆偄偆杮枛揮搢側偺偼惓捈慡懱偺愝寁偵偮偄偰傕媈栤(仸1)傪姶偠傞.
傑乕堦墳GC傪棈傔偨張棟宯偺幚憰側傫偐傕傗偭偰偼偄傞偺偱丄僔僗僥儉偑GC傪慜採偵嶌傜傟偰偄側偄強偱GC偺嫇摦偲崌傢偣傞堊偺奅柺偺張棟偵怓乆擄偟偄栤戣偑偁傞偺偼棟夝偟偰偄傞偮傕傝偩偗偳丄弌棃傞偩偗塀暳偝傟偰慠傞傋偒偱丄偙偆偄偆偁偐傜偝傑側強偵巆偭偰偄傞偺偼偳乕側傫偩傠偆偲偄偆僇儞僕.
帺暘偵娭偟偰尵偊偽丄儊僀儞偱巊偭偰偄傞偺偼C++ + API偺慻傒崌傢偣偱埨掕 (帺嶌尵岅偼慜抜偱偺棟榑偺専徹丒夝愅偑庡梡搑偱偁傞偺偱梋傝乽幚嵺偺乿奐敪偵捈寢偡傞屄強偱偼巊偭偰側偄丄僀儞僞僾儕僞偩偟;-) 偟偰偄傞偺偱丄摿偵峉傞昁梫傕柍偄偲尵偊偽柍偄偑丄慜採抦幆偺栤戣摍偱懡恖悢奐敪偱偼擄偑偁傞偺傕帠幚丄傑乕偦偺曈夛幮帪戙偺僩儔僂儅傕偁偭偰丄偁傞掱搙偺恖悢丒恖嵽偱傕傑偲傕側傕偺偑嶌傟傞娐嫬偺専摙偲偟偰.NET傕怓乆偄偠偭偰偄偨儚働偩偑...偳乕偁偑偄偰傕壓偺掙忋偘偩偗偱丄忋偺昳幙偱傕摢懪偪偑憗偄偺側傜丄偦傫側娐嫬巊偆壙抣偼柍偄偺偩傛側偀丄側傫偰墯傓帠偟偒傝orz
仸1) 屄暿偵懳墳偡傟偽椙偄偲偄偆榖偼丄儔僀僽儔儕偺拪徾奒憌傪廳偹偰偄偭偨帪偵梕堈偵攋抅偡傞丄偦傟帺懱偵偼栤戣偼柍偄偑巊偭偰偄傞僷乕僣偵栤戣偑偁傞応崌丄峏偵偦傟傪曪桳偡傞僷乕僣偱偺嫇摦丄偲. 晽偑悂偗偽壉壆偑栕偐傞揑側(僄儔乕偺)僇僆僗揑敪嶶傪愽嵼揑偵撪曪偡傞帠偵側傞.
---------------
恀柺栚偵儕僜乕僗偵杽傔崬傫偩bmp傪帺慜偺儔僀僽儔儕偲暪梡偡傞宍偱巊偆帠傪峫偊偰傒偨偺偱丄庢傝姼偊偢悩偊抲偒偵偟偰偄偨RLE偺揥奐媦傃(慺嵽嶌惉梡偲偟偰)埑弅張棟傪幚憰偡傞. RLE埑弅帺懱偼杦偳偺慺嵽偱偼巊偄暔偵側傞儗儀儖偱偼柍偄偟丄偮偄偱偵尵偆偲bmp偺RLE偺僐乕僪偼傕偆彮偟儅僔側昞婰偼柍偐偭偨偺偐偲巚偆傛偆側忕挿偝偼偁傞傕偺偺丄僸僢僩僥僗僩偵巊偆傛偆側傾儖僼傽儅僗僋偱偼偦傟側傝偵(10乣15%掱搙傑偱)弅傫偱偔傟傞.
埨堈偵巊偆側傜偄偪偄偪嶌惉偟側偄偱丄僌儘乕僶儖側幆暿巕偲偟偰埖偭偰偟傑偄偨偄強偩偑丄婲摦帪偵main/WinMain偵惂屼偑堏傞慜偵曄姺張棟偑擖傞偺偑僐僗僩揑偵婥偵側偭偰偄偨偺偩偑丄幚嵺傗偭偰傒偨強丄200x200偺夋憸傪RLE揥奐崬傒偱100枃掱搙偱偼慡慠婲摦偺傕偨偮偒偼惗偠偢丄惓捈崱峏側偑傜偵僐儞僺儏乕僞傕懍偔側偭偨傫偩側偀丄側偳偲姶摦偟偰偟傑偭偨. 堦墳曄姺偼擖偭偰偄傞偺偱丄彫妛惗偺崰嵟弶偵嶌偭偨夋憸張棟丄偲偄偆偐怓嬻娫偺曄峏 (MSX偺Screen12偺傾儗偲尵偊偽暘偐傞恖偵偼暘偐傞偐傕) 偼扨弮側曄姺偱偡傜 (BASIC偲偄偆帠傕偁傞偑) 悢帪娫偐偐偭偨偺偑壗偲傕姶奡怺偄.
偨偩埑弅岠棪偲偟偰偼傗偼傝png(偲偄偆偐deflate)摍偺乽偪傖傫偲偟偨乿埑弅張棟傛傝偼奿抜偵棊偪傞偺偱丄朷傑偟偔偼png宍幃摍偱儕僜乕僗偵奿擺偟偰偍偔偺偑椙偄偺偐傕偟傟側偄丄偨偩libpng傪儕儞僋偡傞偲偪傚偭偲偟偨僾儘僌儔儉偱傕200kb掱搙傑偱朿傟偰偟傑偆偺偱丄png張棟偵偮偄偰偼埲慜僼僅乕儅僢僩偺夝愢梡偵嶌偭偨帺慜偺儔僀僽儔儕傪偪傖傫偲幚梡儗儀儖傑偱帩偭偰峴偭偰慻傒崬傫偩曽偑椙偄偐傕偟傟側偄.
傑乕png帺懱偼偲傕偐偔偦乕偡傞偲zlib偺僒僀僘傕婥偵側傞偺偩偑丄傑偩庤帩偪偺deflate幚憰偼zlib傪抲偒姺偊傜傟傞強傑偱廫暘偲偼尵偄擄偄丄揥奐偱3乣5攞丄埑弅偱傕(嵟戝埑弅棪偱)1.5乣2攞掱搙抶偄偟丄埑弅張棟偼lazy match柍偟偱偼zlib傛傝埑弅棪偼0.5乣1%掱搙埆壔偡傞偟丄lazy match偺幚憰偱偼10攞掱搙傑偱抶偔側偭偰偟傑偆:-<
傫乕丄偳乕偟偨傕偺偐.
愭擔偺MDI偺嵟戝壔愗傝懼偊偺儕僒僀僘偺栤戣丄WM_SIZE偱慜偺僗僋儘乕儖僶乕偺壜摦斖埻傪婰壇偡傞宍偱偄偗傞偐偲巚偭偨偺偩偑丄儁僀儞僩僜僼僩偺傛偆側傕偺偱偼忋庤偔峴偔偑丄偦偺懠偺懡悢偺僜僼僩偱偼昞帵斖埻埲奜偵僇儗僢僩埵抲偑偁傝丄捠忢儕僒僀僘帪偵偼 僗僋儘乕儖斖埻挷惍 -> Ensure Visible側張棟偑擖傞偺偱丄Ensure Visible張棟偱帺摦僗僋儘乕儖偑擖傞偲棳愇偵偦偙偱偼僗僋儘乕儖忣曬傪忋彂偒偟側偄儚働偵偼偄偐側偄.
夞旔嶔偲偟偰丄偙傟傜偺帺摦僗僋儘乕儖傪梫偡傞庬椶偺僜僼僩偱偼WM_SIZE偱偼僗僋儘乕儖斖埻偺傒傪曄峏偲偟偰丄幚嵺偵儐乕僓乕偐傜擖椡偑偁傞傑偱僇儗僢僩埵抲傊偺帺摦僗僋儘乕儖傪抶墑偝偣傞宍偑峫偊傜傟傞偑...
帋偟偵埲慜嶌偭偨僥僉僗僩僄僨傿僞偺僗僋儘乕儖偵摨條偺張棟傪慻傒崬傫偱尒偨強...傗偭傁傝彮乆巊偄恏偄orz
偳乕偟偨傕偺偐偲巚偭偨偑丄偦偆偄偊偽VisualStudio6偺僥僉僗僩僄僨傿僞傕偙傫側嫇摦偟偰偄傞偟 (嵟怴偺偼抦傜側偄丄嵟嬤偼GUI偺嶌惉傕娷傔偰僐儅儞僪儔僀儞+僥僉僗僩僄僨傿僞偱偺奐敪偽偐傝偱IDE巊偭偰側偄偺偱:-P) 嵶偐偄巇條傪攃埇偟偰偄傞敜偺MS偺惢昳偱傕偙偺忬嫷偱偁傞側傜丄傗偭傁傝(鉟楉側曽朄偱偼仸1)夞旔晄擻側栤戣偲偄偆強側偺偐偟傜傫orz
偙偺嫇摦偩偲嵟戝壔偱偺塣梡傪儊僀儞偲偡傞偐丄儅儖僠僂僀儞僪僂偱偺塣梡傪儊僀儞偲偡傞偐丄柧妋側巜恓傪愝偗懠曽傪暃師揑偵偺傒偺巊梡傪悇彠偡傞傛偆側僨僓僀儞傪柧妋偵庢傜側偄偲丄傾僾儕偺僨僓僀儞偲偟偰偼尩偟偦偆偱偼偁傞.
儔僀僽儔儕偺婡擻偑僜僼僩偺僨僓僀儞傪寛傔傞偲偄偆壗偲傕杮枛揮搢側忬嫷丄桭恖偑 乽昗弨婡擻偺MDI偼僋僘偩偐傜丄帺暘偱摨偠傕偺嶌偭偨曽偑椙偄傛乿 偲尵偭偰偄偨偺傕偝傕偁傝側傫sigh.
# 傑乕庢傝姼偊偢廗嶌側傫偱丄暿偵偳乕偱傕椙偄偺偩偗偳偹丄戝掞偺傕偺傪嶌傞偩偗偺僀儀儞僩僼儘乕偼捦傔偨偟. 僞僽宆偑椙偗傟偽帺慜偱僞僽宆偺僐儞僥僫嶌傟偽椙偄偩偗偩偟丄偨偩巚偭偰偄偨傛傝傕慖戰巿偲偟偰偺帺桼搙偑掅偄偺偑巆擮偩偗偱orz
仸1) 傑乕傗傠偆偲巚偊偽巕window偺嶌惉慜偵僼儔僌棫偰偰丄WM_SIZE偱巕window偺嶌惉拞偲懠偺window偑嵟戝壔偝傟偰偄傞応崌偼僗僋儘乕儖椞堟偺寁嶼傪pending偟偰丄window偑嵟戝壔夝彍偝傟偰偐偮巕window嶌惉拞偱柍偗傟偽僟儈乕偺WM_SIZE傪旕active側window偵憲怣偡傞偲偐傗傟偽偱偒傞偺偩偗偳偹丄偭偰偦傫側攏幁傒偨偄側帠傗傞側傜慺捈偵僇僗僞儉僐儞僥僫嶌偭偨曽偑儅僔偱偟偐柍偄儚働偱丄僆乕僫乕僪儘乕偱柍棟栴棟暋嶨側帠傪傗傠偆偲偡傞偺偵帡偰傞偗偳丄惓捈懝塿暘婒揰妱偭偰傞偑側丄傒偨偄側:-P
愭擔偺MDI偱偺僗僋儘乕儖僶乕偺審偼怓乆帋峴嶖岆傪偟偨寢壥丄僗僋儘乕儖儔僀僽儔儕偵庤傪擖傟傞宍偵偡傞偺偑堦斣鉟楉偵傑偲傑傞偲偄偆寢榑偵峴偒拝偔.
栤戣偼僋儔僀傾儞僩椞堟偺僒僀僘偑曄傢傞帠偱丄僗僋儘乕儖僶乕偵愝掕偝傟偨抣偑僒僀僘曄峏偺慜屻偱clipping偝傟偰偟傑偆帠偑尨場偱偁傞偺偱丄WM_SIZE偱敪惗偡傞僗僋儘乕儖椞堟偺峏怴偱偼埲慜偺clipping偝傟傞慜偺抣傪曐帩偟偰偍偒丄嵞搙僒僀僘偑曄傢偭偨応崌偵偼偦偺clipping偝傟傞慜偺抣偱曗惓傪峴偆. 僗僋儘乕儖偑幚嵺偵幚峴偝傟偨抜奒偱弶傔偰曐懚偟偰偄偨抣傪幚嵺偺clipping偝傟偨僗僋儘乕儖僶乕偺埵抲偵抲偒姺偊傞偲偄偭偨嬶崌.
偙偺応崌僗僋儘乕儖僶乕偺抂晅嬤偱偼丄僂僀儞僪僂傪嵟戝壔偐傜捠忢僒僀僘偵栠偟偰僗僋儘乕儖僶乕傪怗傜側偄偱丄嵞搙嵟戝壔偟偨応崌偲丄僗僋儘乕儖傪峴偭偰偐傜嵟戝壔偟偨応崌偱暅尦偝傟傞僗僋儘乕儖僶乕偺埵抲偑曄傢傞丄偮傑傝慜屻偱1:1懳墳偱偼柍偔側偭偰偟傑偆偺偱丄惓捈偙傟傕榑棟揑側懳徧惈偐傜偡傞偲丄惓捈偳偆偐偲巚偆偟丄傑偨僼儖僪儔僢僌偱儕僒僀僘偟偰偄傞搑拞偺嫇摦偑捈姶揑偱偼柍偄 (暅尦慜偺僒僀僘埲壓偺応崌偼抂偵挘傝晅偄偨傛偆側摦偒傪偡傞) 婥傕偡傞偺偩偑丄傑偀偙偙偱傗傞偺偑堦斣埨掕偟偨埨掕偟偨曽朄偩傠偆偲寢榑晅偗偨:-<
偦偙傑偱MDI傪婥偵偡傞帠傕柍偄偟丄屄恖揑偵偼摿偵暋悢偺僣乕儖僂僀儞僪僂 + MDI巕僂僀儞僪僂偺宍幃偼寛偟偰巊梡僔乕儞偺僨僓僀儞偲偟偰偼寛偟偰椙偄傕偺偩偲偼巚傢側偄偺偩偑丄MDI + 僼儘乕僥傿儞僌僂僀儞僪僂偺棙揰偲偟偰丄庢傝姼偊偢僜僼僩偑庤偑偐偐偭偰偄偦偆偵尒偊傞(偋 帠傗丄傑偨婡擻傪捛壛偟偨帪偵僨僓僀儞傗僶儔儞僗傪峫偊偢柍愡憖偵婡擻傪捛壛偟偰屻偼儐乕僓乕偵娵搳偘偟堈偄(偍偄 帠丄偦偺忋偱僞僽宆+撈帺僐儞僥僫傛傝偼偦傟偭傐偔尒偊丄掕宆壔偝傟偰偄傞偺偱摉嵗偺斸敾傪偐傢偟堈偄(偍偄偍偄偍偄 帠側偳偑枺椡偱偁傞偲峫偊偰偄傞.
側偳偲彂偔偲丄傆偞偗偰偄傞傛偆偵傕尒偊傞偐傕偟傟側偄偑丄寢嬊偺強偼桳尷側僐僗僩偲偺僶儔儞僗偲偟偰慖戰巿傪帩偭偰偍偒偨偄偲偄偆強偱丄嬌傔偰戝恀柺栚側榖偲偟偰峫偊偰偄傞. 屄恖揑側堄尒偩偑丄杮摉偺堄枴偱揔愗偵儚乕僋僼儘乕傑偱娷傔僨僓僀儞偝傟偨GUI (偵尷傜偢摴嬶慡斒) 偲偄偆偺偼杮摉偵椙偄傕偺偱偼偁傞. 斀柺 (屄恖揑宱尡偩偑) 椺偊僠僃僢僋儃僢僋僗堦偮捛壛偡傞偵傕弉峫傪梫偡傞堊丄奐敪偺僷僼僅乕儅儞僗偲偟偰偼寛偟偰椙偄傕偺偲偼尵偄擄偄.
偦傟偵懳偟丄僐儞僺儏乕僞嬈奅偵偁傝偑偪側 (偦偟偰崱偱傕庡棳傪愯傔傞) 懡婡擻庡媊偲偟偰屻偼 (僇僗僞儅僀僘偲偄偆柤偺) 娵搳偘偲偄偆曽恓偼幚偵妝側榖偱丄偦傟偱偄偰杮棃偺栤戣偼儐乕僓乕師戞偲摝偘傞帠偱丄奐敪懁偺僄僑傪枮偨偟摼傞偟丄庢傝姼偊偢僠僃僢僋儕僗僩偲偟偰懙偭偰偄傟偽姶妎揑側傕偺偼柧妋偐偮揔愗偵斸敾偱偒傞恖偑彮側偄帠傪峫偊傞偲丄摉嵗栤戣偑昞柺壔偡傞帠偼柍偄 (攏幁偵偟偰偄傞傛偆偵尒偊傞偐傕偟傟側偄偑丄宱尡忋偙偺孹岦偼幚幮夛偵偍偗傞奐敪偱戝偄偵嶶尒偝傟傞偲峫偊傞:-P
傑偀寢嬊偺強偼採帵偝傟偨僐僗僩偵懳偡傞慖戰巿偲偄偆僩僐儘偺榖丄杮幙揑側栤戣夝寛偲偟偰偼寛偟偰惓偟偄傾僾儘乕僠偲偼尵偊側偄偑壗傕柍偄傛傝偼儅僔偠傖偹乕丄傒偨偄側偦傫側僇儞僕 (幚嵺撪惢僜僼僩偺奐敪偱偁傟偽丄杮棃庤娫傪偐偗傞傋偒屄強偱偼柍偄偺偱偙傟偱傕廫暘偩傠偆丄晄摿掕懡悢岦偗僷僢働乕僕奐敪偱摨偠帠傪尵偭偨傜僩儖僠儑僢僋傕偺偩偑) ;-)
---------------
偱丄忋偺榖傪摜傑偊偰 (敔掚梀傃偱巊偭偰偄傞) .NET梡偺僗僋儘乕儖儔僀僽儔儕偵傕摨偠廋惓傪壛偊傞帠偵偟偨. 奩摉屄強傪廋惓偟偰摦嶌傪妋擣偡傞偑丄廋惓慜偺摦嶌偲曄傢偭偰偄側偄 (婛偵偙偺帪揰偱姩偺椙偄恖偼婥晅偔偐傕偟傟側偄偑) 30暘嬤偔擸傫偩強偱丄偪傚偭偲巚偄棫偭偰挷傋偰尒傞偲WM_SIZE憡摉偱偺僗僋儘乕儖愝掕偺屄強偱丄僗僋儘乕儖僶乕偵抣傪愝掕偟偨帪揰偱Scroll僀儀儞僩偑敪惗偟WM_H/VSCROLL偱峴偆張棟憡摉偑憱偭偰偄偨orz
傑乕寢嬊張棟拞僼儔僌傪愝偗傞帠偵側傞偺偩偑丄偙偺嫇摦偭偰惓捈僶僇僫儞僕儍僱乕僲(仸1)側傫偰巚偭偨傝偡傞偺偩偑丄傓偟傠偙偆巚偆偺偼彮悢攈側偺偩傠乕偐? 側偍win32偱偼杦偳偺働乕僗偱僾儘僌儔儉懁偱偺曄峏偼僀儀儞僩傪敪峴偟側偄丄偙傟偵傛傝僐儞僩儘乕儖偺忬懺傪僾儘僌儔儉偱愝掕偟偨応崌偵偼偦偺忬懺偱偺僾儘僌儔儉忋偺忬懺偼柧帵揑偵斀塮偡傞昁梫偑偁傞偑丄斀柺旕懳徧揑偁傞偄偼僐儞僩儘乕儖偲奜晹忬懺傪摨婜偝偣傞応崌偵僀儀儞僩僼儘乕偺曽岦偑柧妋偵婯掕偱偒傞.
仸1) 柍榑榑棟揑 (偁傞偄偼僾儘僌儔儅揑偵) GUI偺忬懺偵娭傢傜偢僐乕僪忋偱偺曄峏偱偁偭偰傕僀儀儞僩偑敪惗偡傞曽偑旤偟偔乽尒偊傞乿帠偵偼摨堄偡傞丄幚嵺愄傑偩僟僀傾儘僌偵栄偺惗偊偨掱搙偺僾儘僌儔儉偟偐嶌偭偰偄側偐偭偨帪偵偼帺暘傕偦偆巚偭偰偄偨偺傕帠幚. 偨偩偁傞掱搙 (傑偩廫暘偲偼尵偊側偄偑) 僾儘僌儔儉傪彂偔傛偆偵側偭偰峫偊傪夵傔傞丄嬌榑偡傟偽愝寁忋偺乽旤偟偝乿側傫偰傕偺偼僼儗乕儉儚乕僋丒儔僀僽儔儕壆偺帺屓枮懌偵夁偓偢丄偳傟偩偗旤偟偐傠偆偑丄幚梡偵偍偄偰傓偟傠儈僗儕乕僨傿儞僌傪桿敪偟摼傞愝寁偼僋僘偱偟偐柍偄偲峫偊傞偵帄傞:-P
傑乕丄崱夞偺偼偦偙傑偱偛戝憌側榖偱偼柍偄偺偩偑丄愝寁忋偺乽旤偟偝乿偵忳曕偡傞偲偟偰傕丄偦傟側傜偽儐乕僓乕偺擖椡傪敽偆僀儀儞僩偲曄峏専弌偺僀儀儞僩偼暿宯摑偲偟偰懚嵼偡傞傋偒偩偲傕巚偭偨傝偡傞;-) .NET偵尷傜偢VB帪戙傑偱慿偭偰傕梋傝偙偺審偵怗傟傞恖偑偄側偄偺偼帺暘偺偙偺峫偊曽偼儅僀僲儕僥傿側偺偐側偀(嬯徫)
...傑乕怓乆暥嬪偑懡偄偑丄偙偙偼巹偵偲偭偰偺墹條偺帹偼儘僶偺帹偺彴壆偺栘偺摯偱偁傞偺偱丄強慒偙傫側傕偺偩傠偆;-)
---------------
偦偆偄偊偽愭擔彂偄偨.NET偺deflate偺榖偼4.5偵側偭偰偐傜zlib儀乕僗偵抲偒姺傢偭偨傜偟偄丄偙傟傪埲偭偰椙偟偲偡傞偐丄埥偄偼10擭嬤偔昗弨偲偄偆尐彂偒偺堊偵栶棫偨偢偺婡擻偑偺偝偽傞帠偵側偭偰偄偨丄偲偡傞偐偼幚偵擸傑偟偄強偱偼偁傞偑;-)
尭怓僜僼僩偺柾媅奐敪(仸1)偲偄偆帠偱MDI傪怓乆偄偠偭偰偄傞偑丄偳乕偵傕MDI偺僀儞僞乕僼僃僀僗帺懱偵婔偮偐擄偑偁傞僇儞僕丄嵟戝偺傕偺偼巕Window傪嵟戝壔昞帵偱愗傝懼偊偰巊偆傛偆側塣梡傪峴偭偨応崌偵丄Window偺愗傝懼偊偱旕Active側Window偼彑庤偵嵟戝壔偑夝彍偝傟偰偟傑偆.
偙傟偺壗偑栤戣偐偲尵偊偽僂僀儞僪僂偺僒僀僘偵傛傝Scroll椞堟偑曄傢傞帠偱丄寢壥揑偵儐乕僓乕偲偟偰偼僪僉儏儊儞僩傪愗傝懼偊偰偄傞偩偗偺偮傕傝偑丄愗傝懼偊偨window偺僗僋儘乕儖埵抲偑曄傢傞帠偵側偭偰偟傑偆 (柍榑僗僋儘乕儖埵抲偺廳梫惈偼僾儘僌儔儉偺庬椶偵埶傞偺偱丄偙傟傪埲偭偰MDI偑巊偊側偄偲尵偭偰偄傞偺偱偼柍偄).
嫮堷側曽朄偲偟偰偼婔傜偱傕夝寛嶔偼偁傞偑丄MDI偱偺柾媅奐敪偲偟偰傗偭偰偄傞偺偱丄偦傕偦傕偑僇僗僞儉僐儞僩儘乕儖傪嶌偭偨曽偑儅僔側榖偵偟偐側傜側偄偺偱偁傟偽MDI僀儞僞乕僼僃僀僗偵偮偄偰偙傟埲忋擖傟崬傓偩偗偺壙抣偼柍偄偲偄偆敾抐偵偟偐側傜側偄.
偝偰丄偳乕偟偨傕偺傗傜:-<
仸1) 宱尡忋丄捠忢偺奐敪偲摨儗儀儖偱僀儀儞僩僼儘乕偺懚嵼偡傞僾儘僌儔儉偱側偗傟偽丄愝寁忋偺栤戣偼柧妋偵側傜側偄. Toy Model偺僾儘僌儔儉偽偐傝検嶻偟偰偄偰傕丄寢嬊傑偲傕偵奐敪偡傞偲側傞偲偦偺宱尡偼慡偔栶偵棫偨側偐偭偨傝偡傞偺偱幚嵺偺栤戣偲摨婯柾偱懆偊偰偍偔帠偼廳梫偱偁傞偲峫偊偰偄傞.
---------------
忋偲棈傫偱尭怓儐僯僢僩偵偮偄偰婔偮偐偺傾儖僑儕僘儉僷僞乕儞傪曄峏偟偰専徹偟偰傒偨偑丄尰忬偱偼傑偩僷儗僢僩惗惉偑xPadie偐傜偺攈惗宯傛傝偼傗傗庛偄傕偺偺丄僨傿僓晹暘偱傗傗堦斒揑偱偼柍偄張棟傪偟偰偄傞偺偱丄偦偪傜偺惛搙偱媧廂偟偰偄傞偲偄偆僇儞僕.
柍報偺Padie傛傝偼傑偢椙偄寢壥偼弌偣傞偑丄xPadie偲偟偰僜乕僗偑岞奐偝傟偨傕偺偺攈惗偺寢壥偲斾妑偡傞偲栚棫偮僄儔乕 (揔梡偱偒傞怓偺晄懌偵傛傞嬊強揑側峳傟) 偼弌擄偄偑丄斀柺奼戝偡傞偲傗傗僲僀僘 (奒挷偺峳傟) 偑栚棫偮屄強偑敪惗偡傞応崌偑偁傝丄巊偭偰偄傞怓嬻娫偑堘偆帠傗丄嬊強揑側僷儗僢僩偺廤拞偑戝堟揑側嵞尰搙傪埆壔偝偣傞帠傪峫偊傞偲丄堦奣偵偼尵偄擄偄晹暘傕偁傞偑丄傗偼傝傑偩彮偟媗傔偑娒偄婥偑偡傞sigh.
昳幙偲偄偆帠偱偼JPEG偺僠儏乕僯儞僌傕傗傜側偒傖偄偗側偄婥偑偟偰偄傞偺偩偑丄SAI偺JPEG僄儞僐乕僟偺寢壥偲偐丄libjpeg偲斾傋偰摨堦埑弅棪偱偺儌僗僉乕僩僲僀僘偺検偑偐側傝彮側偄偺偱丄堦墳寢壥偼偦偺傑傑棳梡偟偰傕椙偄偲偺嫋壜偼栣偭偰傞偗偳丄慡偔壗傕帺暘偱専徹偣偢偵巊偆偺傕偳乕偐偲偄偆婥偑偡傞偟. 儕僒僀僘廃傝傕 (摿掕忦審壓偱) 傕偆彮偟昳幙傪忋偘傜傟傞僱僞偼偁傞偺偩偑丄偙偺曈傕娷傔偰傗傜偹偽側傜側偄帠偑嶳愊偟偰偄傞僇儞僕丄壗偲傕壗偲傕X-<
墑乆傗偭偰偄偨摟柧搙晅偒偺尭怓偩偑丄乽堦墳乿掱搙偵偼擺摼偱偒傞傕偺偑弌棃偨偺偱庢傝姼偊偢偺嬫愗傝偲偡傞. 寢嬊崱夞傕1儢寧掱搙偄偠偭偰偄偨帠偵側傞. 尭怓儖乕僠儞偺僒僀僘偼偨偐偩偐1000乣1500峴掱搙 (帋峴夁掱傪巆偡堊懡偔偺僐儊儞僩傾僂僩偑擖偭偰偄傞偺偱惓妋側僒僀僘偼尒愊傕偭偰偄側偄) 偱偁傞偺偱暘検揑偵偼偣偄偤偄2乣3擔掱搙偱彂偗傞検偱偁傞帠傪峫偊傞偲丄壗偲傕攏幁攏幁偟偄偺偐柺敀偄偺偐丄傑乕寢嬊僐乕僪偺峴悢側傫偰傾僥偵側傜傫傕偺側儚働偱 (偣偄偤偄栶偵棫偮偺偼惂屼壜擻惈偺巜昗偲偟偰偩偗偱:-P
偱丄寢壥偼偙傫側嬶崌 (夋憸偼Wikipedia傛傝揮嵹丒廋惓) IE6偱偼僶僌偑偁傞堊丄帺暘偺儊僀儞僽儔僂僓偱偼傑偲傕偵昞帵偝傟偰偄側偄(徫)
 |
幚嵺偼忋偺夋憸偼怓偺孹岦偑柧妋偱丄斾妑揑嬒摍偵暘晍偟偰偄傞僞僀僾偺夋憸側偺偱丄尭怓偺昡壙夋憸偲偟偰偼岦偄偰偄側偄. 傑偨png8偱偼敿摟柧晹暘偺怓暘晍偑懡偄偲埑搢揑偵僷儗僢僩偑晄懌偡傞孹岦偑偁傞偺偱丄偦偆偄偭偨堄枴偱偼偙偺夋憸偺條偵敿摟柧晹暘偵夋憸偲偟偰偺暋嶨側奒挷偑懚嵼偡傞夋憸傕晄岦偒偱偼偁傞 ;-)
側偍摟柧搙柍偟偺応崌偙偺掱搙傑偱偼偄偗傞 (偙偪傜偼崱峏側恖偵偼崱峏側榖偩偗偳丄堦墳懳斾偺堊;-)

帺慜偺僜僼僩傊偺慻傒崬傒傕姰椆偟偨偺偩偑丄帋偟偵嶌偭偰傒偨廳梫椞堟傪儅乕僇乕偱weight晅偗偡傞曽幃偑旕忢偵桳梡偱偁傞帠偑敾柧 (摉幮斾10攞掱搙). 栤戣偼尰忬偺帺嶌僜僼僩偺saver僾儗價儏乕偵偼偦偺傑傑偱偼擖傟崬傔側偄帠偱丄愱梡偺僾儗價儏乕晅偒曐懚夋柺傪梡堄偡傞偺偑懨摉側偺偩偑丄偦乕偡傞偲Animation GIF偲JPEG傕摨條偺僀儞僞乕僼僃僀僗偱偁傞帠偑朷傑偟偄偺偱偳乕偟偨傕偺傗傜丄偲偄偆強.
庢傝姼偊偢彫媥巭偱崱夞偺尭怓儐僯僢僩傪慻傒崬傫偩MDI偺廗嶌 (愝寁梀傃丄峫偊偰尒傟偽toy model掱搙偱偟偐MDI偼偄偠偭偰側偄偺偱丄帋偟偵朸僜僼僩偭傐偄GUI偱傕嶌偭偰丄帺暘偺拞偱僀儀儞僩廃傝偺懱宯壔偩偗偟偰偍偙偆偲偄偆僩僐儘) 偱傕偄偠傝側偑傜傏偪傏偪峫偊偰偄傞強丄寢嬊傑偩巄偔懕偔傫偩傠乕偐(堦墳儅乕僇乕偺weight僶儔儞僗偺挷惍偼姰椆偟偰偄傞偺偱丄尭怓儐僯僢僩帺懱偵庤傪擖傟傞帠偼柍偄偲巚偆偺偩偗偳) sigh.
昞戣偺捠傝丄儗僀儎乕偺堏摦(慜屻娭學)偺undo偲redo偺張棟偑媡偵側偭偰偨丄偙傟偠傖儗僀儎乕偺堏摦傪傑偨偄偩張棟偺undo偱偼張棟懳徾偲側傞儗僀儎乕偑攋抅偡傞偟丄偦偺慜屻偱儗僀儎乕偺嶌惉側傫偐偑偁傞偲懳徾儗僀儎乕帺懱偑曄傢偭偰偟傑偄傑偡orz
擔忢揑偵夋憸張棟偵巊偭偰偄傞偟丄婡擻帺懱傕偛偔昿斏偵巊偆偺偱婥晅偒偦偆側傕偺偩偑丄堄奜偲婥晅偐側偄傕偺偩側偀...undo偺婎杮僨乕僞峔憿側傫偰壗擭傕庤傪擖傟偰偄側偄敜側偺偱丄僶僌偭偰偄偨偲偟偨傜憡摉弶婜偺抜奒偐傜偺敜側偺偩偑(嬯徫)
傑乕堄奜偲偙傫側帠傕偁傞傫偱偡側揑側僇儞僕偱丄屻偼婔偮偐攝晍偟偨屄強偑偁傞傫偱丄尒偰偄傞偐偳偆偐偼抦傜側偄偗偳堦墳偺拲堄彂偒偭偰強偱X-<
# 屻丄愭擔捈偟偨僶僌偱GIF偺曐懚娭楢傪崅懍壔偟偨帪偵摿掕僨乕僞偱lzw僗僩儕乕儉偺枛旜偑彂偒弌偝傟側偄僶僌傕敪惗偟偰傑偟偨丄偙偺廋惓傪偟偨僶乕僕儑儞傪攝偭偨愭偼偐側傝尷掕偝傟偰偄傞敜側偺偱傾儗偱偡偑丄傑堦墳orz
# 偮傑傝偼帺暘偺儈僗偑偁偭偨偺偼昞柧偟偨偺偱丄屻偼偳乕側偭偰傕抦傜傫傛乕偲偄偆帺屓偺撪揑惍崌壔夁掱側儚働偱偡側丄柶嵾晞傪攦偆偺偼妝偟偄帠偱偡傛(儝僀
尭怓儐僯僢僩偺嶌惉拞丄撪惢偱巊偭偰偄傞.NET惢偺夋憸Util偱僋儕僢僾儃乕僪傪夘偟偰揮憲偟偨夋憸偑曄偵儌傾儗偑弌傞偺偱挷傋偰傒偨偺偩偑丄偳偆傕.NET2.0偱偼Clipboard.SetImage/GetImage()偵偰夋憸傪揮憲偡傞偲丄尰嵼偺夋柺偺怓怺搙愝掕偑斀塮偝傟偰偟傑偆傜偟偄 (偮傑傝CF_DIB偱偼柍偔丄CF_BITMAP偺DDB偵側偭偰偟傑偭偰偄傞).
峊偊栚偵尵偭偰傕丄偙傟偱偼價僢僩儅僢僾僨乕僞傪揮憲偡傞偵偼慡偔巊偄暔偵側傜側偄偺偱嫲傜偔偼僶僌偱偼側偄偐偲巚偆偺偩偑 (偙傟傪巇條偲偄偆側傜巇條傪愗偭偨僄儞僕僯傾偺擼幘姵偁傞偄偼恖奿宍惉婜偵偍偗傞摿堎側塭嬁傗梷埑(偋 傪媈傢偹偽側傜側偄:-P) 擛壗偲傕偟擄偟.
傑偀巇曽柍偄偺偱DIB傪帺慜偱DataFormats.Dib偵偮偄偰SetData/GetData()偲偟偰帺慜偱僇儔乕僼僅乕儅僢僩傪曄姺偡傞儖乕僠儞偵抲偒姺偊偨(仸1) 偣偄偤偄400峴掱搙偺僐乕僪側偺偱丄揮梡&僥僗僩偱悢帪娫掱搙偺戝偟偨榖偱偼柍偄偑丄偦偺杦偳偼夋憸僜僼僩偺僐乕僪偐傜偺棳梡偱偁傞偺偱C++ to C#偺曄姺掱搙(仸2)偱丄偙傟傪0偐傜偲側傞偲偦傟側傝偵帪娫偲僥僗僩偺僐僗僩偑偐偐傞榖偱偼偁傞 :-<
晄巚媍側偺偼丄懳張偟偰偄傞傜偟偒僐乕僪偼奀奜偺僜僼僩偺僐乕僪摍偱偼嶶尒偝傟傞傕偺偺丄偙偺栤戣偵尵媦偟偰偄傞忣曬偑庩偺奜彮側偄帠偩傠偆偐丄奆婥偵偟側偄偺偐丄埥偄偼偙偺栤戣偑栤戣偵側傞傛偆側夋憸傪埖偆僜僼僩傪嶌傞婡夛偑幚偼彮側偄偺偐丄偝偰.
仸1 埨堈偵傗傞側傜Stream偵彂偒弌偟偰BITMAPFILEHEADER晹暘偺僆僼僙僢僩傪壛偊偰柍棟栴棟曄姺偡傞曽朄傕偁傞偑丄BMP偩偗偱傕婔偮偐偺僿僢僟偺僶乕僕儑儞偑桳傝丄儔僀僽儔儕偺彂偒弌偟巇條傪埫栙揑偵婜懸偡傞曽朄偼幚憰偲偟偰偼旕忢偵椙偔側偄&嵶偐偄僶乕僕儑儞僠僃僢僋偟偰曄姺偡傞埵側傜摨偠帠側偺偱寢嬊帺慜傪慖戰偟偨;-)
仸2 偟偐偟C#偼偍傠偐悽偺杦偳偺乽嵟嬤偺乿崅媺尵岅偱偺僶僀僫儕偺埖偄恏偝偼偳偆偵偐側傜側偄傕偺偐丄DB偲偺愙懕傗XML, Unicode側偳傕椙偄偑丄暘栰偵傛偭偰偼 (偲偄偆偐嬈柋傾僾儕埲奜偱偼) 僨乕僞偲偟偰偺僶僀僫儕偺埖偄偼偦傟偲摨掱搙偐偦傟埲忋偵廳梫側榖偱偁傞婥偑偡傞偺偩偑. 偁傞偄偼帺暘偑擭傪偲偭偨偩偗偱丄婛偵僶僀僫儕偺廳梫惈偼幐傢傟偰偄傞偲偐偹(嬯徫)
---------------
.NET偼堄奜偲偙偺庤偺栤戣偑偁傝丄愭擔傕Animation GIF偺僥僗僩傪偟偰偄偨強丄昗弨偺ImageAnimator偺僞僀儈儞僌惂屼偑僟儊僟儊
(偲偄偆偐傑偲傕偵摦嶌偟偰偄側偄儗儀儖偱晄惓妋) 偱寢嬊帺慜偺僗働僕儏乕儔傪嶌傞帠偵側偭偨傝丄Deflate廃傝偺傾儖僑儕僘儉幚憰偼偦傟偙偦
(暿搑Deflate傪幚憰偟偰傒傞偲暘偐傝堈偄偑) 埨堈側LZSS偺嵟懍堦抳 (3暥帤堦抳偡傞強偱偦傟偱廔傢傝) 偱偡傜梱偐偵儅僔側埑弅棪傪弌偣傞傛偆側崜偄幚憰偵側偭偰偄偨傝偲怓乆摢偑捝偄.
傑偀Deflate偺掅惈擻偼廃曈摿嫋傑偱峫椂偟偨寢壥丄柍擄側幚憰偺傒偵巭傔偨偲傕岲堄揑偵偼峫偊摼傞偑丄偦傟偱傕偦偺埑弅惈擻偼偙傟偱Deflate傪柤忔偭偨傜嵓媆偠傖側偄偐丄偲偄偆儗儀儖偱旕忢偵埆偄(仸3)
幚嵺奐敪娐嫬偺僥僗僩偲偟偰嶌惉偟偰偄傞婔偮偐偺.NET惢偺撪惢僜僼僩偱傕丄寢嬊嵶偐偄栤戣偵懳張偡傞堊偵儔僀僽儔儕憡摉偺婡擻傪帺慜偱幚憰偟偨傝丄偐側傝偺晹暘傪Win32傗InteropServices宯偺屇傃弌偟丒曄姺偑愯傔偰偄偨傝偱丄傑傞偱偐偮偰偺VB傾僾儕偑撪晹偱傗偨傜偲Win32傪屇偽側偄偲巊偄暔偵側傜側偐偭偨忬嫷偺嵞尰偱偁傝丄寛偟偰妟柺捠傝偺埖偄堈偄戙暔偲傕尵偄擄偄 (偦傟偱傕GUI傾僾儕偵偮偄偰偼Java傗ActionScript偺娐嫬偵斾傋偨傜傑偩儅僔偩偑)
偁傞堦掕婯柾傑偱偼巊偄堈偔丄偦偺憐掕傪奜傟偨強偱偼杮枛揮搢偵側偭偰偟傑偆強偼丄尰嵼偺奐敪娐嫬偺僶儀儖傪峔抸偡傞拞偱丄尵岅偲儔僀僽儔儕偺拪徾壔奒憌傪愊傒忋偘丄傛傝崅搙側僾儘僌儔儉傪嶌傟傞傛偆偵偡傞偲偄偆敪憐偦偺傕偺偵崻杮揑側寚娮偑偁傞偺偐...偆乕傓.
傑丄幚嵺偺強僜僼僩偺幚尰傊偺梫媮偼奐敪娐嫬偱偼柍偔丄嵟掅尷廃埻偺懠偺僜僼僩偲偺斾妑偐傜惗偠傞傕偺偩丄偲偄偆強偵偙偺栤戣偺僊儍僢僾偺杮幙偑偁傞偺偐傕偟傟側偄. 栜榑偙傟偼嵟掅尷偺忬嫷傪愢柧偟偨偩偗偺榖偱丄杮幙揑偵偼僜僼僩偺梫媮偼僜僼僩偑懱尰偡傞摴嬶偑偳偺傛偆偵偁傞傋偒偐丄偲偄偆強偐傜掕傔傜傟傞傋偒偱偁傞偺偼尵偆傑偱傕柍偄偑:-P
仸3 慡偰傪挷傋偨儚働偱偼柍偄偑丄暋悢僨乕僞偱斾妑偟偨強丄堦墳僇僗僞儉僴僼儅儞僥乕僽儖偑巜掕偝傟偰偄傞偑丄幚嵺偼屌掕偺僴僼儅儞僥乕僽儖傪巊偭偰偄傞柾條偱丄壓庤傪偡傟偽Deflate偱婯掕偝傟偰偄傞屌掕僴僼儅儞僥乕僽儖傪巊梡偟偨応崌 (偙傟傕埑弅惈擻偼摉慠埆偄) 傛傝傕埆壔偡傞応崌偡傜偁傞丄摨堦曽恓偱嶌惉偝傟偰偄傞偺偐儖乕僠儞偑嫟梡側偺偐(仸4)丄Deflate傪巊偆PNG偺埑弅棪偵偮偄偰傕.NET儔僀僽儔儕傪捠偟偰惗惉偟偨傕偺偼嬌傔偰埑弅棪偑埆偄丄偲偄偆偐僨乕僞偵廫暘側曃傝偑偁傞僨乕僞偱尦僨乕僞傛傝戝偒偔側傞働乕僗偑懡乆偁傞帪揰偱埑弅儔僀僽儔儕偲偟偰偼婛偵榑奜側婥傕偡傞偑 :-<
仸4 PNG埑弅偺応崌丄僀儞僨僢僋僗傪彍偔僼儖僇儔乕媦傃僌儗僀僗働乕儖偺応崌偵偼儔僗僞扨埵偺僼傿儖僞張棟偵傛傞DPCM偺寢壥丄僨乕僞偺曃傝偑尠挊偵側傞堊丄慺捈偵LZSS傪揔梡偡傞傛傝傕丄廫暘側挿偝偵払偟偰偄側偄僨乕僞偵偮偄偰偼屻抜偺僴僼儅儞晞崋偵擟偣偰偟傑偆曽偑埑弅棪偲偟偰偼憤偠偰椙偄寢壥傪弌偡孹岦偵偁傞丄偙偺堊Deflate晹偵偮偄偰偼捠忢偺Deflate偲偼彮偟堘偭偨儌乕僪偱摦嶌偝偣傞曽偑椙偄帠偵側傞.
婛偵儊儞僥僫儞僗僼僃乕僘偵擖偭偰偄傞傛偆側嬶崌偱丄巚偄偮偄偨帪偩偗恑峴拞傒偨偄側儁僀儞僩僜僼僩嶌惉偱偡偑 (傑乕敿暘偼傾儖僑儕僘儉傗棟榑丒壖愢偺僥僗僩僾儔僢僩僼僅乕儉偲壔偟偰偄傞傫偱偦傫側傕偺偱偡偑)
巚偄棫偭偰Animation GIF偲PNG8偺彂偒弌偟傪捛壛偟偰傒偨丄偱PNG8傪僒億乕僩偡傞側傜2抣摟柧搙偩偗偱側偔敿摟夁傕僒億乕僩偡傞偺偑摉慠偩傠乕偲巚偄丄尭怓儐僯僢僩偵庤傪擖傟偨偺偑塣偺恠偒丄尭怓嬻娫偺4師尦壔偼敿擔(偲偄偆偐悢帪娫(徫)偱姰椆偟丄偦傟側傝偺寢壥偼摼傜傟偨偺偩偑丄奺僠儍儞僱儖偺旝柇側僶儔儞僗偑擄偟偔丄旝挷惍傗儘僕僢僋偺嵞専徹傪孞傝曉偡帠1廡娫梋傝丄偪側傒偵尰嵼傕宲懕拞.
...峫偊偰尒傟偽慜偺(敿摟柧傪僒億乕僩偟側偄)尭怓儐僯僢僩傪嶌偭偨帪傕0儀乕僗偱曌嫮傪巒傔偰偐傜 1乣2廡娫掱搙偱儌僲偼弌棃偨偺偩偑丄寢嬊怓乆挷惍偟偰崱偺宍偵側傞偵偼3儢寧掱搙偐偐偭偰偄傞偺偩傛側偀sigh
偲偄偆帠偱僱僢僩偱廍偭偰偒偨條乆側僞僀僾偺夋憸傪尭怓偟偰偼栚傪嵶傔偰慡懱偺僶儔儞僗妋擣丄奼戝偟偰岆嵎奼嶶僲僀僘偲奒挷偺僶儔儞僗傪妋擣丄峏偵懠偺僜僼僩偲斾傋偰傾儖僑儕僘儉揑偵壗偑婲偒偰偄傞偐偺悇應傪墑乆孞傝曉偡丄惓捈栚偼旀傟傞偟丄墑乆摨偠夋憸偽偐傝尒偰偄傞偲偦偺偆偪壗偑椙偄偺偐暘偐傜側偔側偭偰偒偰丄偲偄偭偨嬶崌.
偦傕偦傕儘僕僢僋揑偵柧妋側夝偑偁傞傕偺側傜傕偭偲妝側偺偩偑丄尭怓張棟偺応崌丄榑棟揑偵惓偟偄嵟揔壔偼傓偟傠丄戝嬊偱偺擣抦揑側堘榓姶傪憹暆偟偨傝丄慡懱偺僶儔儞僗偑愯桳柺愊偲怓嵎偺旝柇側峧堷偒偱惉棫偟偰偍傝丄偁偪傜偺惛搙偑忋偑傟偽偙偪傜偺惛搙偑壓偑傞偲偄偭偨嬶崌偱丄擛壗偲傕偟擄偟丄偦傕偦傕偑鑷抣張棟偺夠側偺偱丄旝暘楢懕揑側僷儔儊乕僞偺曄摦偑偦偺傑傑斀塮偝傟傞儚働偱柍偔丄挷惍偑捈姶揑偵偼峴偐側偄偺偑壗偲傕擄偟偄丄愭擔傗偭偰偨僽儔僔僄儞僕儞偺嵞挷惍傕摿堎揰晅嬤偺嫇摦偺挷惍偼宱尡懃揑偱惓捈揇徖偩偲巚偭偰偄偨(徫)偑丄尭怓張棟偺僶儔儞僗挷惍偼傎傏慡堟偑偦傫側嬶崌orz 夋憸傪墑乆尒懕偗傞嶌嬈偲崌傢偣惓偵抧崠偺傛乕側忬懺偑宲懕拞.
---------------
庢傝姼偊偢傑偩巄偔懕偒偦偆偩偗偳丄堦墳彂偒弌偟婡擻偱嶌偭偨Animation GIF偼偙傫側嬶崌.

尭怓儐僯僢僩偺惈擻偵嬅偭偨偺偩偑丄偙傟偠傖慡慠暘偐傝傑偣傫側orz
...敿摟柧偼傑偩偦偙傑偱媗傔傜傟偰側偄偗偳orz
偮偄偱偵Animation GIF偵偮偄偰挷傋偰偄傞偲丄(桳柤強傑偱娷傔) 岞奐偝傟偰偄傞杦偳偺夋憸Viewer偱姰慡偵Animation GIF偺巇條傪僒億乕僩偟偨傕偺偑杦偳柍偄帠偵婥晅偄偨傝丄摉慠僽儔僂僓偱偼昞帵偱偒傞偺偱丄棊偲偟強偼偦傟偵崌傢偣傞偺偑懨摉偩偲巚偆偺偩偑丄実懷偺僽儔僂僓偲偐傑偱峫偊傞偲僋僆儕僥傿偼惓捈傾僥偵偱偒側偄偟丄壗偲傕偼傗...orz
偦傠偦傠偆偭偲偍偟偄儎僣偵(帺暘偑)側偭偰偒偰偄傞婥偑偡傞偺偱旕忢偵嫲弅側偺偱偡偑m(_ _)m
BS_DEFPUSHBUTTON偺埖偄偵偮偄偰偼彮乆僋僙偑偁傞傛偆偱偡丄夁嫀偵挷傋偨儊儌偺敳悎偱偡偑
丒BS_DEFPUSHBUTTON僗僞僀儖傪愝掕偡傞偺偼1偮偺僐儞僩儘乕儖偩偗
丒ID偵IDOK/IDCANCEL傪愝掕偟偨応崌偼IDOK偺儃僞儞偵BS_DEFPUSHBUTTON偑愝掕偝傟偰偄傟偽偦偺傑傑IsDialogMessage偱張棟偝傟傞偑丄偦傟埲奜偺id傪巊梡偡傞応崌帺慜Window (not 僟僀傾儘僌) 偱偼DM_GETDEFID偵墳摎偡傞昁梫偑偁傞.
側偍DM_GETDEFID/DM_SETDEFID偼DefDlgProc偱張棟偝傟傞憐掕偺傕偺偱偁傝丄忋偼帺慜偱儌乕僟儖儖乕僾傪幚憰偡傞応崌偺庤弴偵側傞丄DM_GETDEFID/DM_SETDEFID偼WS_USER/WM_USER+1偑妱傝摉偰傜傟偰偍傝IsDialogMessage偼偙傟傪敪惗偡傞壜擻惈偑偁傞偺偱WM_USER/WM_USER+1偼巊偆傋偒偱偼柍偄.
側偍IDOK/Enter偵偮偄偰偼偙傟偱椙偄偑丄IDCANCEL/Escape偵偮偄偰偺暿id偱偺嵞尰曽朄偼晄柧.
偲偄偆帠偱忋偺榖傪庣傜側偄偲僼僅乕僇僗偺堏摦摍偱僨僼僅儖僩偺崟榞偑昞帵偝傟側偐偭偨傝偲偄偭偨栤戣偑敪惗偟傑偡丄偲偄偆偐偙偺榖帺懱帺暘偱傕偡偭偐傝朰傟偰傑偟偨偑(^^;;;;
IDCANCEL偺嫇摦偺暿ID偱偺嵞尰偑暘偐傜側偐偭偨&柺搢側傫偱帺暘偼IDOK/IDCANCEL傪巜掕偡傞曽朄偟偐巊偭偰側偄偱偡(徫)丄丄丄偲偄偆偐僟僀傾儘僌帺懱偑儕僜乕僗偲僐乕僪偺2売強偺廋惓偑昁梫偵側傞&ID傪偄偪偄偪掕媊偟側偗傟偽側傜側偄偺偑柺搢偲偄偆嬶崌側傫偱嵟嬤偼杦偳巊偭偰側偐偭偨傫偱偡偗偳丄偦偆偄偊偽帺慜偺儁僀儞僩僜僼僩偺OK儃僞儞偵BS_DEFPUSHBUTTON愝掕偟偰側偄偱偡偹丄姰慡偵BS_DEFPUSHBUTTON偺懚嵼帺懱朰傟偰傑偟偨(戝娋)
偟偐偟丄丄丄僼傿儖僞偺僟僀傾儘僌偺廋惓偩偗偱50屄嬤偔偁傞偺偱傔傫偳偄丄儔僀僽儔儕偵傕僨僼僅儖僩儃僞儞偺嶌惉偱娭悢1屄捛壛偟側偒傖偄偗側偄偟丄峏偵尰嵼儊儞僥僫儞僗拞偺慡偰偺僜僼僩偵斀塮偝偣傞偲丄丄丄偁丣乕orz
堷偒懕偒TANE偝傫強偺6/18偺榖(^^;;;
Trackbar偺審偼傕偆彮偟崿傒擖偭偨榖偺柾條丄嫇摦傪妋擣偟傑偟偨偑僜乕僗傪尒偨強偐側傝偺僷僱儖偱hbrBackground傪愝掕偟偰偄傞偺偱攚宨傑偱娷傔偨嵞昤夋偑昿斏偵憱偭偰偟傑偭偰偺僠儔偮偒偺傛偆偵傕尒偊傑偡丄僐儞僩儘乕儖偺恊window偺嵞昤夋 -> 僐儞僩儘乕儖帺懱偺嵞昤夋偲偄偆僇儞僕偱. common control偺僶乕僕儑儞偵傛偭偰旝柇偵嫇摦偑堘偆偺偼婎杮揑偵ver5/6偼暿僐乕僪側傫偱柍岠嬮宍偲嵞昤夋偺敪惗偺僞僀儈儞僌傗昿搙偑堘偆堊偠傖側偄偐偲巚偄傑偡.
帺暘揑偵偼hbrBackground偼NULL偵偟偰偟傑偭偰嵟掅尷偺昤夋偺傒WM_ERASEBKGND偲WS_CLIPCHILDREN傪慻傒崌傢偣偰巊偭偰偄傞偺偱偡偑丄攚宨昤夋偼壜擻側尷傝嵟慜柺偺巕window偺傒偵偟偰僐儞僥僫側偳偦偺椞堟偑巕window偱塀傟偰偟傑偆傕偺偵偮偄偰偼嵟掅尷偺偼傒弌偡椞堟偺傒偺徚嫀偵巭傔偰偍偔傛偆側僇儞僕偱愝掕偡傞偲嵞昤夋帪偺僠儔偮偒偼寉尭偱偒傑偡. WS_CLIPCHILDREN偑曋棙偱偡偑丄僗僋儘乕儖側傫偐偺搒崌忋偦傟偑忋庤偔摦偐側偄応崌偼恊window偺嵞昤夋偱巕window偺椞堟傪柍岠嬮宍偐傜彍奜偡傞傛偆側張棟傪峴偆応崌傕偁傝傑偡.
# 偪側傒偵嫇摦偺榖偼椺偊偽ANSI偱埖偆偲僐儌儞僐儞僩儘乕儖偺ver5/6偱edit僐儞僩儘乕儖偺儊僢僙乕僕寢壥帺懱堘偆傕偺傪曉偟傑偡(徫丄丄丄偊側偐偭偨傝偡傞X-<
Window偺傾僋僥傿僽偺審偼僜乕僗傪尒偨僇儞僕ModalWindow偺攋婞(DestoryWindow) -> EnableWindow(恊Window)偲傗偭偰偄傞婥偑偡傞偺偱偡偑 (娫堘偭偰偄偨傜僗儈儅僙儞) 偙傟偩偲堦帪揑偵傾僾儕偵桳岠側Window偑懚嵼偟側偄堊Windows偺僼僅乕僇僗儅僱乕僕儍偑忋庤偔張棟偱偒側偔側傝傑偡丄偺偱惓夝偼EnableWindow(恊Window)傪峴偭偰偐傜ModalWindow偺DestroyWindow傪屇傇偺偑儌乕僟儖儅僱乕僕儍偺幚憰偺僙僆儕乕偵側傞傫偩偦偆偱偡 (by MS偺拞偺恖偑彂偄偨杮傛傝).
忋偺傛偆側昁梫惈偑偁傞偺偱Modal Dialog偺廔椆偼DestroyWindow偱偼柍偔愱梡偺API(EndDialog)偑偁傞偺偩傛丄偲備乕傛乕側榖偑彂偄偰偁傝傑偟偨(徫)
---------------
偙偪傜偼慡偔PC偑夡傟傞婥攝偑柍偄偱偡丄Win2k側傫偱偦傠偦傠懳墳僜僼僩傕彮側偄 (偲偼尵偊嵟嬤偼巗斕僜僼僩偼杦偳巊偄傑偣傫偟丄敿暘塀撡忬懺側傫偱偦傟掱怴偟偄奐敪娐嫬傪捛偆昁梫惈傕柍偄(偭偰偦傟偱偄乕偺偐(敋巰) ) 偺偱偡偑丄偙傟偼偙傟偱崲偭偨傕偺偱偡(嬯徫)
TANE偝傫強偺6寧16擔僱僞丄昗弨僐儞僩儘乕儖偺Trackbar丄妋偐偵憖嶌惈揑偵偼僀儅僀僠側晹暘偼偁傞偺偩偗偳嵞昤夋廃傝偭偰偦傫側曄側嫇摦偟偨偐側乕偲婥偵側偭偨偺偱僥僗僩僾儘僌儔儉 偙傟尒傞尷傝偁傞掱搙偺嵞昤夋偼敪惗偡傞偺偩偗偳丄 偦傟掱僼儕僢僇乕偑寖偟偄偲偄偆掱偱傕柍偄婥傕偟傑偡偑丄丄丄偨偩梋傝Trackbar傪攝抲偟偨Window偱儕僒僀僘壜擻側傕偺偼嶌偭偰偄側偄偺偱丄懠偺僐儞僩儘乕儖偑戝検偵偁偭偨応崌偲偐偼枹妋擣偱偡偑(^^;; 傕偟偐偟偨傜儕僒僀僘廃曈偺僀儀儞僩屇傃弌偟偱晄梫側嵞昤夋偑擖偭偰偟傑偭偰偄傞偲偐?
Rebar(CoolBar)偼傎傏慡偔巊偭偰側偄偺偱暘偐傝傑偣傫m(_ _)m 屄恖揑偵僪僢僉儞僌偡傞UI偭偰寵偄(仸1)側偺偱摿偵僯乕僘偑柍偗傟偽傑偢巊傢側偄僔儘儌僲側偺偱(徫)
# 屻丄幚奞傪柧帵弌棃偢丄幚憰幰偺庡媊偺晹暘傕偁傞偺偱彂偙偆偐柪偭偨偺偱偡偑丄window偺儌乕僟儖幚峴廔椆帪偵恊window傪BringWindowToTop偵偡傞偺偼傗傜側偄曽偑椙偄婥傕偟傑偡丄晛捠偼Windows偺昗弨張棟偱埲慜偺window偑暅婣偟傑偡偟丄僼僅乕僇僗廃傝偺嫇摦偼偲傕偡傞偲帺僾儘僙僗埲奜偵傕暋悢Window傊偺捠抦側偳偑棈傫偱妱偲僨儕働乕僩側晹暘側偺偱丄懡暘栚棫偭偨栤戣偼柍偄偲偼巚偆傫偱偡偗偳. 傾僾儕偱柍梡偵SetForegroundWindow傪屇傇偺偲摨庬偺婋偆偝偑偁傞偲偄偆偐. 傑偀丄屄恖揑堄尒偲偄偆帠偱(^^;;;;;;;;;
仸1) 寵偄偲偄偆偲姶忣揑側昞尰偱偡偑丄UI偺応崌敊慠偲偟偨憡懳埵抲偱婰壇偟偰偄偨傝偡傞偺偱丄偦傟偵傛傝夋婜揑偵儚乕僋僼儘乕偑夵慞偡傞偺偱側偗傟偽拞搑敿抂側僇僗僞儅僀僘梫慺偼柍偄曽偑椙偄偲偄偆偺偑屄恖揑側奐敪曽恓. 摿偵僣乕儖僶乕偺埵抲側傫偰夋柺僒僀僘偵崌傢偣偰僐儘僐儘埵抲偑曄傢偭偨傝偡傞偺偱丄偦傟傪庢傝崌偊偢壗偱傕暲傋偰屻偼儐乕僓乕偵搳偘偭傁偭偰偺偼扨弮偵僾儘僌儔儅乕偺僨僓僀儞偺曻婞側婥偑偡傞儚働偱;-)
---------------
偙偙巄偔偼壗偲側偔巚偄棫偭偰Flash ActiveX偺儂僗僩側傫偧彂偄偰偄偨傝丄ExternalInterface偺屇傃弌偟偼Shell View(IE)傪儂僗僩偡傞応崌偺SetExternalDispatch/GetExternal偲堘偭偰僀儀儞僩僔儞僋宱桼偱_IShockwaveFlashEvents::FlashCall偑屇傃弌偝傟傞僇儞僕.
偱傕偭偰儕僋僄僗僩偼XML偺宍幃偱棃傞偺偱偦偺堊偩偗偵COM偺XML僷乕僒傪巊偭偨傝儔僀僽儔儕傪扵偟偨傝偑柺搢偩偭偨偺偱丄寢嬊帺慜偱XML僷乕僒傪彂偄偨傝. 塃僋儕僢僋/儊僯儏乕僉乕偼寢嬊忋庤偄曽朄偑柍偐偭偨偺偱儊僢僙乕僕儖乕僾偱swf僐儞僥僫偺巕懛偺応崌偵儊僢僙乕僕偦偺傕偺傪嶦偡 (幚嵺偵偼憲傝愭傪恊window偵曄峏偟偰偟傑偆) 宍偱懳張偟偰傒偨傝.
swf偺僗僥乕僕僒僀僘偼寢嬊COM宱桼偱偼埨掕偟偨傕偺偑庢傟側偄偺偱swf傪夝愅偡傞宍偱幚憰偟偨傝丄側偍swf偺埑弅偼愭摢8僶僀僩傪彍偄偰zlib偺deflate偦偺傑傑. 偮偄偱偵swf偺峔憿傪怓乆挷傋偰傒偨傝丄婎杮偼僠儍儞僋宆側傫偩偗偳丄僒僀僘偑尩偟偐偭偨帪戙偺嶻暔偱偦偙偐偟偙偵價僢僩僗僩儕乕儉側埖偄偑昁梫偱僂儞僓儕偟偰傒偨傝. 偦傟偱傕堦墳swf偐傜儕僜乕僗傪傇偭偙敳偔帠偑偱偒傞傛偆偵側偭偨傝丄傑乕怓乆僌僟僌僟偲丄偨偩偦傫側偵柺敀偄傕偺偠傖偁傝傑偣傫側(嬯徫) 傑偀偣偄偤偄swf傪exe偵偟偰exe婲摦偺応崌偼僼傽僀儖偺曐懚傗僎乕儉僷僢僪偺僒億乕僩傪捛壛偡傞掱搙偐側乕傒偨偄側偦傫側僇儞僕丄傑偀朞偒傞傑偱偲偄偆嬶崌.
TANE偝傫偲偙偺Window僋儔僗偺榖丄偞偭偔傝偲偟偐撉傫偱側偄偱偡偑丄婥偵側偭偨屄強傪彮乆
丒Window僋儔僗偺娗棟偼WM_CREATE偱偼柍偔WM_NCCREATE偱傗傞曽偑椙偄偐傕丄弴彉偲偟偰偼WM_NCCREATE -> WM_CREATE -> WM_DESTROY -> WM_NCDESTROY偩偭偨偲巚偄傑偡.
丒僐儞僩儘乕儖偺僼僅儞僩偼GetStockObject(DEFAULT_GUI_FONT)偑巊偊傑偡丄屻偼GetSysColorBrush側傫偐傕攋婞偟側偔偰椙偄偺偱曋棙.
丒Window僋儔僗偺僀儞僗僞儞僗傪柧帵揑偵嶍彍偟偰偄傞屄強偑尒摉偨傜側偐偭偨偺偱偡偑 (尒棊偲偟偰偨傜僗儈儅僙儞) GC擟偣偲偡傞偲僨僗僩儔僋僞偱僴僢僔儏偐傜彍嫀偟偰偄傞偗偳丄偦傕偦傕僴僢僔儏偵搊榐偝傟偰偄傞尷傝GC偱偼嶍彍偝傟側偄偺偱偼? (偙偺曈D尵岅偺巇條傕梋傝徻偟偔側偄偺偱娫堘偭偰偄偨傜僗儈儅僙儞)
丒忋偺榖偲棈傫偱丄Window僴儞僪儖偺庻柦偲僴僢僔儏撪偺搊榐忣曬偺娗棟偑堦抳偟偰偄側偄偲丄屻偐傜嶌傜傟偨Window偺僴儞僪儖抣偑丄慜偺攋婞偟偨僴儞僪儖偲廳暋偟偰偨応崌偵儅僘偄偺偱偼丄偲偐.
傑偀偙傫側強偱偟傚偆偐(^^;;
嵟嬤偼帺暘偼偮偄偧晄惛偵側偭偰丄暋嶨側張棟埲奜偼wndProc撪偵捈彂偒偟偰偟傑偭偰傑偡丄僪儔僢僌張棟偲偐儅僂僗僀儀儞僩偑暘偐傟偰偄傞偲柺搢&壜撉惈偑壓偑傞偟丄僣乕儖愗傝懼偊偺幚憰側傫偐偼儊僀儞Window偺wndProc偐傜僣乕儖偺wndProc偵暘婒偝偣偰昁梫側僀儀儞僩偩偗僼僢僋偝偣傞偺偱on乣僴儞僪儔幃偩偲暘婒僐乕僪偩偗偱偊傜偄帠偵側傞偲偐丄傑乕偦傫側嬶崌偱(嬯徫)
---------------
CMYK偺榖偲棈傫偱丄怓乆僼僅乕儅僢僩傪挷傋偰偄偨強丄壗帪偺娫偵偐16bit float偑IEEE巇條偵側偭偰偄偨.
偲偄偆帠偱曄姺僐乕僪傪彂偄偰傒偨偗偳丄惛搙堟偑3寘偟偐柍偄偺偱怓乆旝柇. 壗偲尵偆偐傑偀丄愊嬌揑偵巊偆傕偺偠傖側偄側乕偲偄偆偐偦傫側嬶崌 :-<
偦傟埲奜偵偼TIFF偺僒儞僾儖僼僅乕儅僢僩巜掕偵SAMPLEFORMAT_COMPLEXIEEEFP側傞傕偺傪尒偮偗偰丄壗偱傕傾儕偩側乕偲柇偵姶怱偟偨傝丄偱傕愄偼堦晹偺摿庩側僾儘僌儔儉偱偟偐巊傢傟偰偄側偐偭偨SAMPLEFORMAT_IEEEFP偼嵟嬤偼HDR岦偗偲偟偰巊傢傟偰偄傞偲偐丄PhotoShop傕CS2偐傜懳墳偟偰偄傞偲偐. 偦傟埲奜偵偼奺夋憸宍幃偺ICM僾儘僼傽僀儖偺杽傔崬傒曽朄傪挷傋偰偨傝丄傑乕偦傫側僇儞僕偱僌僟僌僟偲.
偄傗傑乕丄娭楢偟偰偄傞傫偱椙偄婡夛偩偐傜挷傋偰傞偩偗偱丄幚嵺偵偼CMYK傗僇儔乕僾儘僼傽僀儖偼幚憰偟側偄偲巚偆偗偳丄帺嶌儁僀儞僩僜僼僩偺png偺僈儞儅儖乕僠儞偡傜奜偟偰傞埵偩偐傜丄偪側傒偵怓曄姺偼ICM API偵娵搳偘偱偡(徫)
偙偙悢擔偼CMYK偱偺僾儗價儏乕傪偄偠傞丄幚憰梫慺偲偟偰偼傎傏慡偰懙偄丄僥僗僩慻傒崬傒偱傕栤戣柍偔摦偄偰偼偄傞偑丄幚嵺偵塣梡偡傞偵偼扨偵CMYK偺僾儘僼傽僀儖巜掕偩偗偱柍偔丄偁傞掱搙尩枾側僇儔乕僾儘僼傽僀儖偺塣梡偑媮傔傜傟傞偺偱偳乕偟偨傕偺偐丄偲偄偭偨僇儞僕.
僇儔乕僾儘僼傽僀儖側傫偧丄幚嵺僌儔僼傿僢僋僜僼僩傪巊偭偰偄傞憤恖岥偐傜偡傟偽9妱偺恖娫偵偼堄枴偑柍偄傕偺偱丄柍梡側崿棎傪堷偒婲偙偡偲偄偆帠偱偼1妱偵偲偭偰桳梡偱傕9妱偵偲偭偰偼奞埆偵偟偐側傜側偄丄幚嵺惗敿壜側抦幆偱偺僇儔乕僾儘僼傽僀儖偺塣梡側傫偰栚傕摉偰傜傟側偄忬嫷偱偁傞偟 (幚椺偼CMYK側偳偺僉乕儚乕僪偱専嶕偡傟偽晠傞掱弌偰偔傞).
摨條偵AdobeRGB偺曇廤偲偐傕摨偠梫慺偱幚憰偼偱偒傞偗偳丄偙傟傕傑偨杦偳偺恖偵偲偭偰偼帠懺傪峏偵柍梡偵傗傗偙偟偔丄暘偐傝擄偔偡傞偩偗偵偟偐側傜側偄 (偦偟偰偦傟傪夞旔偡傞偵偼丄側偳偲偄偆柍梡側僲僂僴僂偑棫偪忋偘傜傟傞帠偵側傞).
偝偰丄偳乕偟偨傕偺偐 :-<
# 傑偀丄偁傞掱搙偼CMYK僾儗價儏乕傕壠掚梡僾儕儞僞偱偺報嶞偱曄怓偟堈偄怓傪妋擣偡傞偺偵傕巊偊傞 (6怓偱+LC,LM偺応崌偼孹岦偼帡偰偄傞) 偺偱丄幚梡惈奆柍偲傕尵偊側偄偑.
# 摨偠傛偆側榖偲偟偰偼夋憸偺僺僋僙儖僒僀僘偲dpi偺榖傕柍梡側崿棎偺尦偩傢側丄強慒僐儞僺儏乕僞偵偲偭偰偼dpi側傫偰幚懱偺柍偄儊僞僨乕僞偵夁偓側偄儚働偱丄傑偀偙偪傜偼僇儔乕僾儘僼傽僀儖傛傝偼扨弮側榖側偺偱傑偩儅僔偱偼偁傞偑丄幚嵺偵偼報嶞偟側偄側傜僺僋僙儖僒僀僘偩偗偱dpi側傫偰梫傜側偄偟丄壠掚梡報嶞偱偼偳偆偣彑庤偵奼戝弅彫偑擖傞偺偱栚埨掱搙偺帺屓枮懌掱搙偵偟偐側傜傫偺偩偗偳丄杦偳偺僜僼僩偵偁偭偰偦傟偑尦偱崿棎偑偁傞偺傪尒傞偲傗偭傁傝壗偐攏幁偘偰偄傞婥偑偡傞丄傑偀悽奅偺抐楐偭偰儎僣傗偹 :-P
擟堄嬮宍偱昞尰偝傟傞嶌恾揑側僷乕僗嵗昗偺擟堄暘妱偲嵗昗曄姺偺僥僗僩
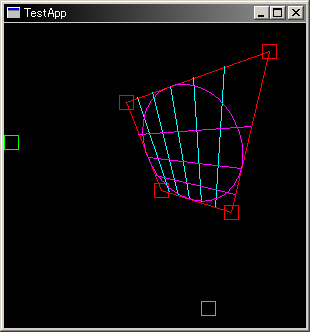
傑偀偙傫側傕偺偐偲偄偆僇儞僕丄擔婰偵嵹偣傞偺偱彫偝側夋柺偵墴偟崬傔傞宍偱偐側傝榗傫偱尒偊傞偑丄2丒3暘妱偺曗彆慄傪堷偄偰傒傞偲偪傖傫偲僷乕僗暘妱偲偟偰惉棫偟偰偄傞偺偑暘偐傞偲巚偆丄偨偩懡暘僷乕僗掕婯偼幚憰偟側偄偲巚偆偑(仸1) ;-)
仸1) 壗偲尵偆偐丄僷乕僗嶌惉偵昁梫側梫慺傪堦捠傝忔偭偗傞偲CAD揑偲偄偆偐帠柋揑偲偄偆偐帠慜寁夋揑偲偄偆偐丄僜僼僩偺帩偮報徾偑壗偲傕寴嬯偟偄or懅嬯偟偄戙暔偵側傝偦偆側傫偱丄偣偄偤偄僌儕僢僪掱搙偱婥寉偵埖偊傞掱搙偺幚憰偵棊偲偟偙傔傞側傜傾儕側傫偱偡偗偳偹 :-<
幚憰姰椆
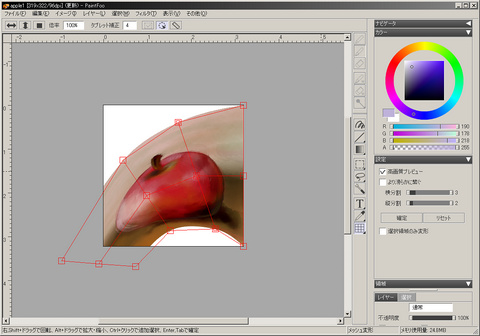
傑乕壗偲尵偆偐僟儔僟儔偲丄嵟嬤偼擔婰傪彂偔偺傕柺搢側僇儞僕偱丄崲偭偨傕偺偩.
偦偺屻偁傞僜僼僩偺懱尡斉偱摨條偺婡擻傪帋偡丄儊僢僔儏曄宍帺懱偼偁傝偑偪側婡擻偺傛偆偱堄奜偲幚憰偟偰偄傞僜僼僩偼彮側偄丄惓捈儚僋儚僋偟側偑傜帋偟偨偺偩偑丄幚嵺偵偼偦偺梋傝偺幚憰偺崜偝偵曫傟曉傞帠偟偒傝丄尰帪揰偱帺嶌偺傕偺偼岞奐偡傞堄巚偼柍偄偺偱梋傝尵偊偨媊棟偱偼柍偄偑丄偦傟偱傕偙傟偼奐偄偨岥偑嵡偑傜偸偲偄偆報徾偱丄偙偺僜僼僩偵尷傜偢丄偲傝偁偊偢偺僠僃僢僋儕僗僩傪杽傔傑偟偨揑側幚憰偍傛傃偦偺傛偆側幚憰傪峴偆僾儘僌儔儅偺懚嵼丒恖惗(偋 偵偮偄偰偼丄偄偢傟偼弆惔^H^H惀惓偝傟偹偽側傜偸偲巚偆帠偟偒傝 :-<
擫偱傕暘偐傞Windows僾儘僌儔儈儞僌偺師偵傗傞傋偒帠
Win32偺曌嫮偱彮偟慜偵桭恖偵暦偐傟偰懄摎偱偒側偐偭偨撪梕丄傆偲暿偺桭恖僾儘僌儔儅偲榖偟偰偄偨帪偵丄扨婡擻偺API偺攃埇偐傜幚嵺偵僾儘僌儔儉傪彂偗傞傛偆偵側傞強偺奐偒偼壗張偵偁傞偐偲偄偆榖偱弌偨撪梕傪婔偮偐梾楍.
丒僂僀儞僪僂僴儞僪儖偵僨乕僞傪寢傃晅偗傞曽朄偲偦偺庻柦娗棟
僋儔僗僗僞僀儖偱Win32僾儘僌儔儉傪傗傞側傜昁恵丄C偱偁偭偰傕暋嶨側僾儘僌儔儉偼偙偺曈傪傗偭偰偍偐側偄偲傑偢柍棟
丒僇僗僞儉僐儞僩儘乕儖偺帺嶌
儃僞儞偺傛偆側傕偺偱傕椙偄偺偱慺偺Window偐傜EnableWindow,SetFocus摍偵斀墳偟丄儅僂僗憖嶌偵懳偟偰揔愗偵僉儍僾僠儍傪峴偄丄僟僀傾儘僌儅僱乕僕儍摍偲暪梡偟偰傕偪傖傫偲僼僅乕僇僗摍偑摦嶌偟偨忋偱儔僀僽儔儕壔偟偰暋悢嶌惉偡傞応崌偵傕捠忢僐儞僩儘乕儖偺嶌惉丒娗棟偲摨掱搙偺庤娫偱嵪傓傕偺傪嶌傞.
丒擖椡偲夋柺峏怴偺庤弴
擖椡偵崌傢偣偰撪晹忬懺傪峏怴偟丄嵞昤夋傪敪峴偡傞帠偱WM_PAINT撪偱慡偰峏怴偡傞儌僨儖偱偺幚憰傪峴偆丄摉偨傝慜偺榖側傫偩偗偳寢峔偙偺曈偺榖偑尒偊偰側偄僾儘僌儔儅傕懡偄丄娫堘偭偰傕旕忢帪埲奜偼GetDC偱昤夋側傫偰偟偪傖偄偗側偄.
丒僆儞儊儌儕偺僼儗乕儉僶僢僼傽偲偟偰偺dib偺巊梡偲夋柺峏怴
偙傟傑偨堄奜偲摉偨傝慜側傛偆偱徻嵶偑彮側偄榖丄GUI傗僐儞僩儘乕儖昤夋偱嬅偭偨傕偺傪嶌傞嵺偺婎杮拞偺婎杮. 屄恖揑偵偼80擭戙偺8bit儅僀僐儞帪戙傪岅傞僾儘僌儔儅偱丄帺嶌偺僼儗乕儉僶僢僼傽僋儔僗/儔僀僽儔儕傪帩偭偰側偄攜偼恵傜偔慡偰僷僠儌儞偩偲巚偭偰椙偄偱偡:-P
丒儌乕僟儖儅僱乕僕儍偺帺慜幚憰偲僗儗僢僪偛偲偺Windows偺儊僢僙乕僕僉儏乕幚憰偺攃埇
偙傟傑偨堄奜偲摉偨傝慜偺傛偆偱帒椏偺彮側偄榖丄僼儗乕儉儚乕僋偺僐乕僪摍偱偟偐幚嵺偺僒儞僾儖傪尒傞婡夛偼彮側偄偑丄嵶偐偄GUI偺嫇摦傪幚憰偡傞応崌擟堄偺応強偱偺儌乕僟儖幚峴偺幚憰傗偦偺帪Window偵壗偑婲偒偰偄傞偺偐偺攃埇偼昁恵.
傑偨Send/Post儊僢僙乕僕偑Windows偵傛偭偰偳偺傛偆偵僉儏乕忋傗儊僢僙乕僕儕僗僩 偵捛壛偝傟偰張棟偝傟偰偄傞偺偐傕偪傖傫偲幚憰儗儀儖偱攃埇偟偰側偄偲曄側棊偲偟寠偵偼傑傝崬傫偩傝偡傞塇栚偵.
偲傑乕偙傫側強偱偟傚偆偐丄夵傔偰尒傞偲偳傟傕偙傟傕杮摉偵婎杮揑側丄摉偨傝慜偺榖偱偟偐柍偄偺偱偡偑丄堄奜偲僱僢僩偱尒偰偄偰傕忣曬偑柍偄忋偵丄帺暘偺宱尡忋傾僾儕僾儘僌儔儅傪柤忔偭偰偄偰偙偺曈慡偰偪傖傫偲墴偝偊偰偄傞僾儘僌儔儅偭偰梋傝尒偐偗側偐偭偨傝偟傑偡.
(傑偀巹偺廃埻偑梋傝偵斶嶴側偩偗偲偄偆壜擻惈傕偁傝慡懱偺孹岦偲偡傞偵偼彮乆忣曬晄懌偱偼偁傝傑偡偑)
偦傟埲奜偵偼幚嵺偺儔僀僽儔儕偺幚憰偺椺戣偲偟偰丄嶌惉偝傟偨僐儞僩儘乕儖偺埵抲傪婰壇偟偰WM_SIZE偱帺摦偱嵞攝抲傪峴偆儗僀傾僂僩儅僱乕僕儍偲偐丄 壖憐僗僋儕乕儞偺埵抲偩偗愝掕偟偰偍偗偽僗僋儘乕儖嵗昗偩偗偱僂僀儞僪僂偺僗僋儘乕儖偑幚憰偱偒傞儔僀僽儔儕偲偐丄傕偭偲扨弮側強偱偼僗僾儕僢僞僐儞僩儘乕儖偺幚憰偲偐丄傑偀偦偺曈傪傗偭偰偍偔偲僟僀傾儘僌傑偱偼嶌傟傞傫偩偗偳丄偦傟埲忋偺 暋嶨側傾僾儕偲側傞偲暘偐傜側偄偲偄偭偨忬嫷傪懪奐偡傞尞偵偼側傞偐傕偟傟傑偣傫.
幚嵺姷傟偰偔傞偲C#偺GUI僨僓僀僫掱搙偱偱偒傞埵偺GUI偼API偱傕偦傫側偵庤娫偑偐偐傜側偔側偭偨傝偟傑偡丄偊偊丄偄傗儅僕偱;-)
---------------
摟柧悈嵤偲偟偰偺昞尰椡偲偟偰椺偺儗僀儎乕偺寁嶼幃偑偳乕偺偙乕偺丄偱偙傟偑寢壥

尦乆偺忔嶼崌惉偱偺摟柧悈嵤昞尰偩偲偙傫側伀嬶崌

側偺偱丄巊偄曽偵傛偭偰偼旕忢偵岠壥揑丄摟柧悈嵤宯偺昞尰傪偟偨嵺偵幚嵺偺奊偺嬶偵斾傋敪怓偑埆偄偲偄偆栤戣偵偮偄偰偼傎傏夝徚壜擻&揾傝崬傫偩帪偺梊應偲偄偆堄枴偱傕尨怓偦偺傑傑側偺偱栤戣柍偟. 柍榑枩慡偲偄偆儚働偱柍偔丄榓巻摍傊偺偵偠傒偲偄偆揰偼傑偩傑偩偱偼偁傞偑. 偪側傒偵梡朄偲偟偰偼揾傝偺儗僀儎乕偲姡憞嵪傒偺儗僀儎乕傪摨偠儌乕僪偱2枃梡堄偟偰敿摟柧昤夋 (SAI偺儅乕僇乕偵傎傏憡摉) 偱揾傝儗僀儎乕偵昤夋丄揔摉側強偱姡憞嵪傒偺儗僀儎乕偵揮幨偺孞傝曉偟偲偄偭偨嬶崌.
傑偀栤戣偼PSD偵曐懚偡傞偲儗僀儎乕儌乕僪傪嵞愝掕偟側偗傟偽側傜側偄強丄偦傠偦傠撈帺宍幃偺曐懚偺幚憰傪専摙偡傞帪婜偐.
---------------
傑偀偦傫側嬶崌偱婥晅偗偽2011擭丄柧偗傑偟偰偍傔偱偲偆偛偞偄傑偡. 嶐擭偼恎撪帠偱怓乆偁偭偨撪梕傪彂偒偨偔側偐偭偨偺偱杦偳擔婰偼彂偄偰傑偣傫偱偟偨偑丄傕偆偦傟傕夁偓偨帠丄傏偪傏偪埲慜偺儁乕僗偱摦偗傞傛偆偵偟偰峴偒偨偄偲巚偭偰傑偡m(_ _)m
偦偆偦偆丄幵偺柶嫋庢傝傑偟偨丄搶嫗偱偼幵傪強桳丒堐帩偡傞偺偼擄偟偄偱偡偑丄堦墳丄偹.